다항식(Polynomial) ADT
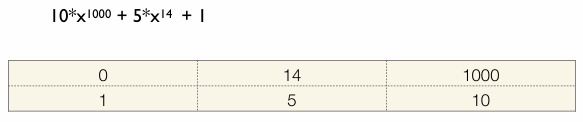
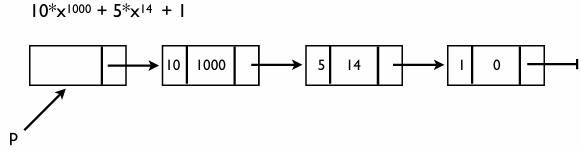
다항식을 자료구조로 표현할 때의 핵심은 계수(Coefficient)와 지수(Exponent)를 어떻게 저장하고 관리하느냐에 있다 예시 수식:
- 이 식은 지수가 1000인 항, 14인 항, 그리고 상수항으로 이루어져 있다
배열을 이용한 구현
배열로 다항식을 구현하는 방식은 크게 두 가지로 나뉜다
지수를 인덱스로 사용하는 방식
배열의 인덱스를 지수로, 해당 방의 값을 계수로 저장한다. 이렇면 구현이 매우 직관적이고 특정 항을 찾는 속도가 빠르다. 하지만 문제점이 있는데, 바로 처럼 항은 몇 개 없는데 지수가 큰 경우, 0으로 가득 찬 수많은 빈 공간이 생겨 메모리 낭비가 심각해진다

(지수, 계수) 쌍으로 저장하는 방식
배열에 실제 값이 있는 항의 지수와 계수만 쌍으로 묶어 저장한다
구조체 정의
typedef struct {
int Coefficient; // 계수
int Exponent; // 지수
} polynomial;
polynomial terms[MAX_TERMS];- 특징: 빈 항을 저장하지 않으므로 메모리를 훨씬 아낄 수 있다
연결 리스트를 이용한 구현
각 항을 하나의 노드로 만들어 연결하는 방식이다
구조체 정의
typedef struct Node *PtrToNode;
struct Node {
int Coefficient; // 계수
int Exponent; // 지수
PtrToNode Next; // 다음 항을 가리키는 포인터
};
typedef PtrToNode Polynomial;연결 구조
장점:
- 필요한 항만큼만 노드를 생성하므로 메모리 효율성이 매우 높다
- 다항식의 항을 추가하거나 삭제할 때 배열처럼 데이터를 밀고 당길 필요가 없다
단점: 포인터를 관리해야 하며, 특정 항을 찾으려먄 처음부터 차례대로 훑어야 한다 ()
커서
커서
커서란 포인터 없이 만드는 연결 리스트이다. 포인터를 사용할 수 없는 환경에서 연결 리스트를 구현하기 위해 고안된 방법이다
작동 원리: 실제 메모리 주소 대신 배열의 인덱스를 화살표처럼 사용한다
구조:
- 커다란 배열을 미리 만들어두고, 각 칸(노드)에 데이터와 다음 칸의 번호를 저장한다
- 인덱스 0은 포인터에서의
NULL과 같은 역할을 수행하여 리스트의 끝을 나타낸다
장점:
- 시스템의 포인터 기능을 쓰지 않고도 리스트 구조를 만들 수 있다
- 메모리 할당과 해제를 배열 내에서 직접 관리할 수 있다
예시
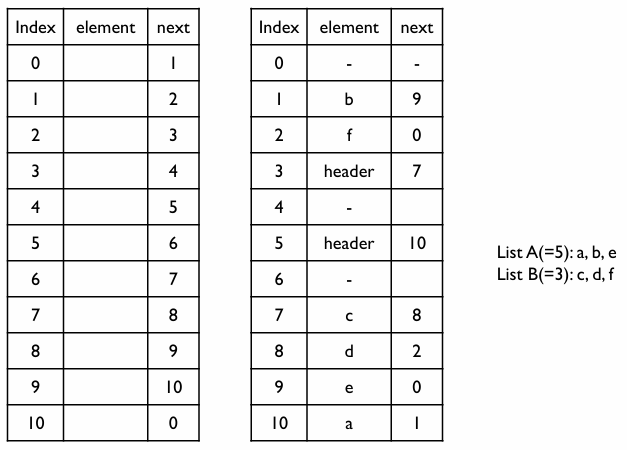
- 리스트 A (시작 인덱스 5):
a, b, e- 인덱스 5(header) 인덱스 10(
a) 인덱스 1(b) 인덱스 9(e) 0 (끝)
- 인덱스 5(header) 인덱스 10(
- 리스트 B (시작 인덱스 3):
c, d, f- 인덱스 3(header) 인덱스 7(
c) 인덱스 8(d) 인덱스 2(f) 0 (끝)
- 인덱스 3(header) 인덱스 7(
커서 구현
타입 선언
typedef int Position;
typedef Position List;
typedef int ElementType;
struct Node
{
ElementType Element;
Position Next;
};
struct Node CURSOR[CURSOR_SIZE]; //전역 배열 사용Find 함수 구현 특정 데이터를 찾는 로직이다. 연결 리스트처럼 포인터를 따라 이동 하는 것이 아니라. 배열 인덱스를 참조하며 이동한다
Position Find( ElementType X, List L ) {
Position P;
// CursorSpace[L].Next는 배열 내의 '다음 인덱스 번호'를 가져옴
P = CursorSpace[L].Next;
// P가 0(NULL 역할)이 아닐 동안 반복
while( P != 0 && CursorSpace[P].Element != X )
P = CursorSpace[P].Next; // 인덱스 번호를 타고 다음 칸으로 이동
return P;
}스킵 리스트
스킵 리스트
연결 리스트의 가장 큰 단점은 검색이 느리다는 것이다. 원하는 값을 찾으려면 처음부터 끝까지 돌아야 한다. 스킵 리스트는 이 문제를 해결하기 위해 나온 자료구조이다
특징:
- 졍렬된 리스트 위에 여러 층의 지름길을 만든다
- 검새구시 많은 요소를 한 번에 건너뛰어 목적지에 도달한다
- 기대 검색 시간은 높을 확률로 이다
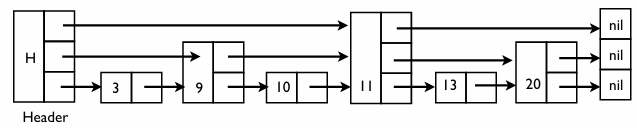
- 위층으로 갈수록 더 넓은 범위를 한 번에 건너뛸 수 있게 된다
완벽 스킵 리스트
구조체 정의
typedef struct skip_node *s;
struct skip_node {
element_type element; // 데이터
int level; // 해당 노드가 가진 층의 높이
struct skip_node **forward; // 다음 노드들을 가리키는 포인터 배열 (이중 포인터)
};메모리 할당
먼저 노드 자체의 메모리를 할당한다. 그후 해당 노드의 높이(level + 1)만큼 포인터 배열 공간forward)을 따로 할당해야 한다
특징 및 한계 이 자료구조가 ‘완벽’하다고 불리는 이유는 이진 탐색 트리처럼 완벽한 균형을 이루기 때문이지만, 실제 사용에는 큰 제약이 있다
- 재구성의 어려움: 데이터를 하나 삽입하거나 삭제할 때마다 전체 리스트의 층 구조를 모두 다시 조정해야 한다(배열에서 중간에 값을 넣을 때 데이터를 미는 것보다 훨씬 복잡한 작업이다)
- 최대 높이: 허용 가능한 최대 노드 수가 일 때, 헤더 노드의 최대 높이(Size)는 이 되어야 효율적이다
검색
스킵 리스트의 노드는 일반 노드와 다리 여러 층의 포인터를 가질 수 있는 가변 크기노드이다, 각 노드는 최대 개의 포인터를 가진다
검색 방식: search(k)
- 찾았다면 (
k = next_key): 검색 종료 - 더 가야 한다면 (
k >= next_key): 현재 층에서 오른쪽으로 한 칸 이동한다 - 지나쳤다면 (
k < next_key): 현재 층보다 한 단계 아래 층으로 내려가서 다시 오른쪽을 살핀다
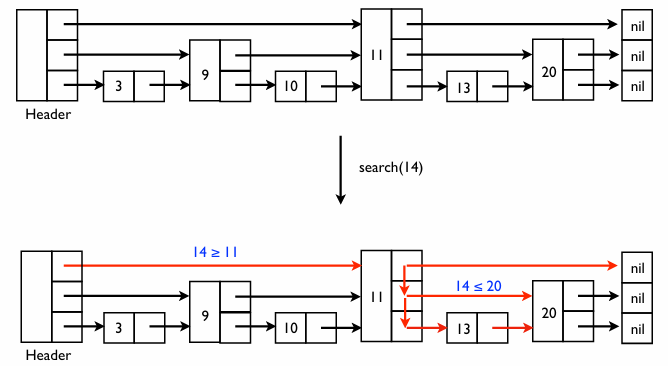
랜덤 스킵 리스트
랜덤 스킵 리스트
정렬된 연결 리스트를 기반으로 하되, 확률적인 방법을 동원해 검색, 삽입, 삭제 성능을 획기적으로 높인 자료구조이다
일반적인 연결 리스트는 특정 값을 찾기 위해 처음부터 끝까지 훑어야 하지만(), 랜덤 스킵 리스트는 여러 층의 ‘지름길’을 만들어 평균 의 속도를 보장한다
특징: 새로운 데이터를 삽입할 때, 이 노드가 몇 층까지 올라갈지를 무작위 방식으로 결정한다
삽입
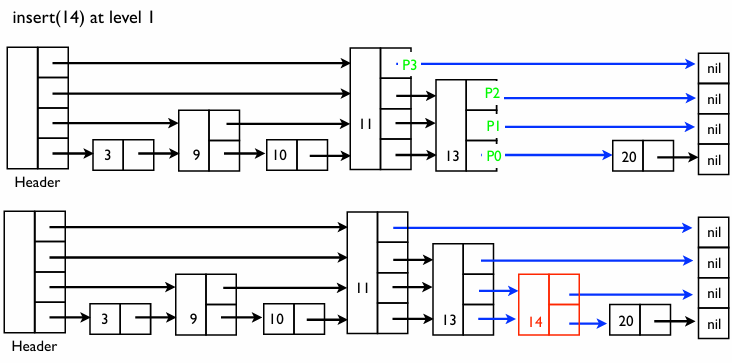
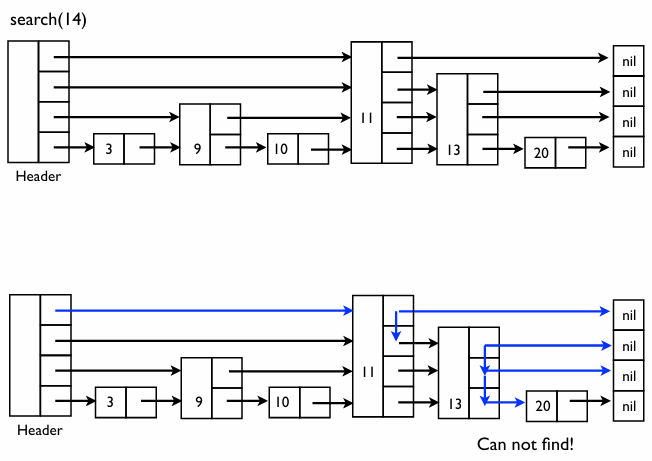
1단계: 탐색 새로운 값(예: 14)을 넣기 위해 먼저 해당 값이 리스트에 있는지 찾는다
- 과정: 헤더에서 시작해 높은 층의 지름길을 타고 가다가 14보다 큰 값을 만나면 한 층 내려온다
- 결과: “Can not find!” (14가 없음을 확인). 이 과정에서 14가 들어갈 위치가 13과 20 사이라는 것을 알아낸다
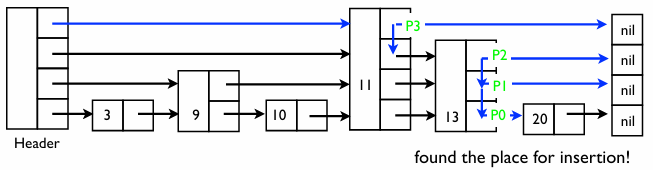
2단계: 삽입 지점 추적 14를 삽입할 때, 각 층에서 14의 왼쪽에 위치하게 될 노드들을 기억해야 한다
- 포인터들이 바로 그 지점들 이다
- 이 노드들의 ‘다음 칸(Next)’ 화살표를 나중에 새 노드 14로 연결해줘야 하기 때문이다
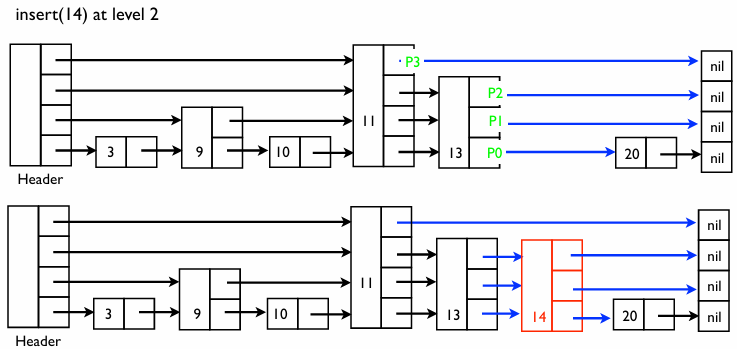
3단계: 무작위 층 결정 이 부분이 무작위 스킵 리스트의 핵심이다
- 원칙: 새 노드 14의 높이(층)는 미리 정해진 것이 아니라 무작위로 결정한다
- Level 2로 결정되면 3개의 화살표를 가진다
- Level 1로 결정되면 2개의 화살표를 가진다
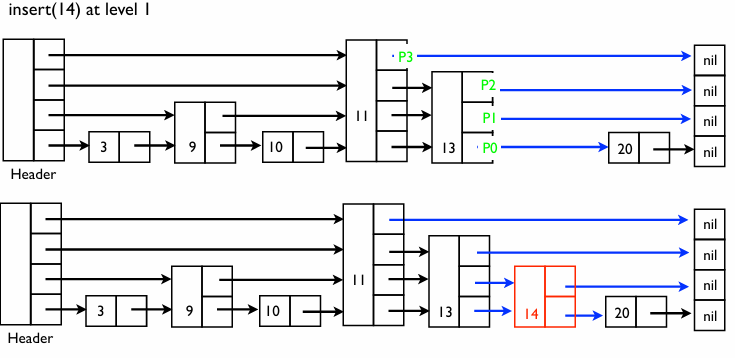
4단계: 연결 층이 결정되면 아까 찾아둔 지점들의 화살표를 새 노드 14에 연결한다
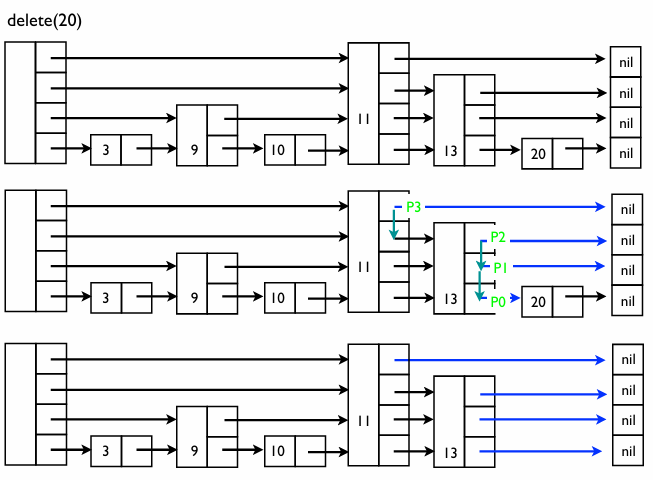
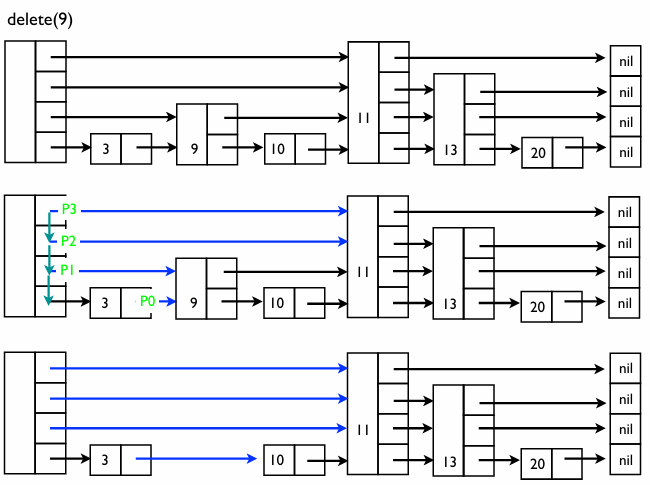
삭제
스킵 리스트에서 노드를 삭제하는 것은 단순히 해당 데이터를 지우는 것이 아니라, 그 노드를 가리키고 있던 이전 노드들의 화살표를 모두 수정하는 작업이다
과정:
- 탐색 및 추적: 삭제할 값(예: 20 또는 9)을 찾으면서, 각 층에서 그 값의 바로 왼쪽에 위치한 노드들()의 위치를 기록한다
- 연결 수정: 기록해둔 이전 노드들의 화살표가 삭제할 노드를 건너뛰고, 삭제할 노드가 가리키던 다음 노드를 직접 가리키도록 업데이트한다
- 메모리 해제: 리스트에서 완전히 고립된 노드를 메모리에서 제거한다
예제