스택 ADT
스택
스택은 데이터의 삽입과 삭제가 리스트의 한쪽 끝에서만 일어나는 순서 있는 리스트이다
핵심 연산
push(X, S): 스택 의 가장 위에 요소 를 삽입한다pop(S): 스택 에서 가장 최근에 삽입된 요소를 삭제하고 반환한다top(S): 현재 스택의 가장 위에 있는 요소를 확인한다
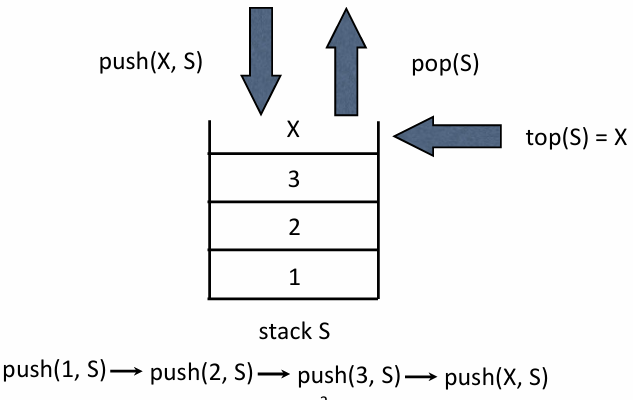
LIFO 원리
스택의 가장 큰 특징은 후입선출 방식이다. 늦게 들어온 데이터가 가장 먼저 나가는 구조를 말한다
예시:
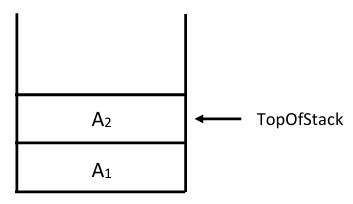
스택의 구조 정의: array 기반
스택을 배열로 구현할 때는 데이터를 담을 배열과, 현재 가장 위에 있는 데이터의 위치를 가리키는 인덱스가 필요하다
정적 배열 방식(Static Array): 미리 정해진 크기만큼 배열을 생성하는 방식이다
top = -1: 스택이 비어있음을 의미한다
#define MAX_STACK_SIZE 100 // 스택의 최대 크기를 100으로 고정
/* 스택에 저장할 데이터(요소)의 형식을 정의 */
typedef struct {
int key; // 데이터를 식별하는 키 값
/* 여기에 다른 필드들을 추가할 수 있음 */
} ElementType;
/* 고정된 크기의 배열을 직접 선언하여 스택으로 사용 */
ElementType stack[MAX_STACK_SIZE];동적 배열 방식(Dynamic Array - StackRecord): 구조체를 사용하여 스택의 용량과 상태를 관리하며, 필요한 시점에 메모리를 할당한다
/* 스택 구조체를 가리키는 포인터 타입을 'Stack'으로 정의 */
typedef struct StackRecord *Stack;
/* 스택의 상태와 데이터를 관리하는 구조체 */
struct StackRecord
{
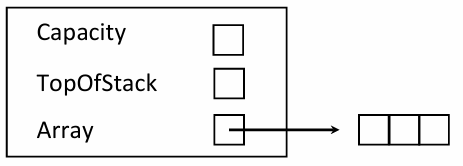
int Capacity; // 스택이 가질 수 있는 최대 요소 개수 (용량)
int TopOfStack; // 현재 가장 위에 있는 데이터의 위치(배열 인덱스)
// 비어있으면 -1, 데이터가 하나 있으면 0이 됩니다.
ElementType *Array; // 실제 데이터들이 저장될 동적 배열을 가리키는 포인터
};
주요 연산 및 조건
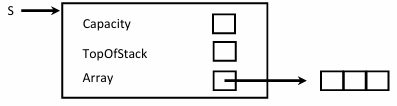
CreateStack 스택을 생성한다. 메모리를 두 번 할당해야 한다. 하나는 스택 관리용 구조체, 또 하나는 실제 데이터를 담을 배열이다
Stack CreateStack(int MaxElements) {
Stack S;
S = malloc(sizeof(struct StackRecord)); // 1. 구조체 메모리 할당
S->Array = malloc(sizeof(ElementType) * MaxElements); // 2. 배열 메모리 할당
S->Capacity = MaxElements;
S->TopOfStack = -1; // 빈 상태로 초기화
return S;
}
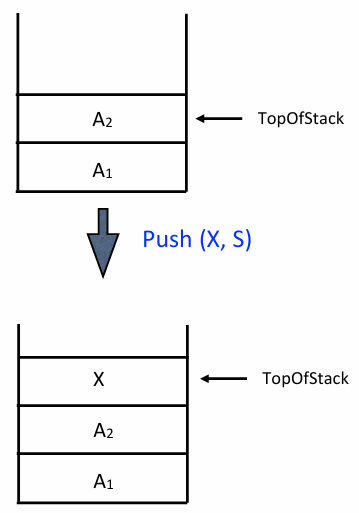
Push
데이터을 삽입한다. 가득 찼는지 먼저 확인한 후, top을 1 증가시키고 그 자리에 데이터를 넣는다
void Push(ElementType X, Stack S) {
if (IsFull(S)) {
Error("Full stack");
} else {
S->Array[++S->TopOfStack] = X; // top을 먼저 증가시킨 후 저장
}
}
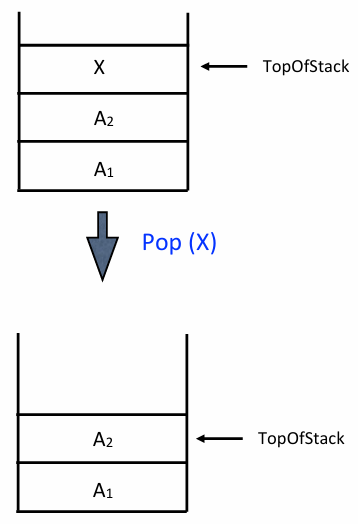
Pop
데이터를 추출한다. 비어있는지 확인한 후, 현재 top 위치의 데이터를 반환하고 top을 1 감소시킨다
// Pop: 데이터를 꺼내고 제거함
ElementType Pop(Stack S) {
if (IsEmpty(S)) {
Error("Empty stack");
} else {
return S->Array[S->TopOfStack--]; // 값을 먼저 반환한 후 top 감소
}
}
Top
데이터를 확인한다. 데이터만 확인하고 top의 위치는 그대로 유지한다
ElementType Top(Stack S) {
if (!IsEmpty(S)) {
return S->Array[S->TopOfStack];
}
return 0; // 에러 처리
}
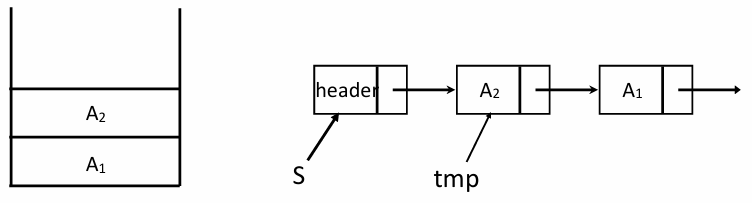
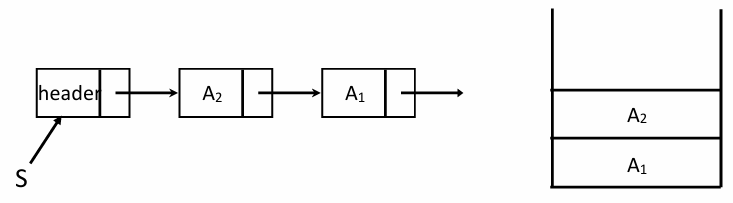
스택의 구조 정의: Linked List 기반
연결 리스트로 스택을 만들 때는 헤더 노드를 사용한다. 스택의 top은 항상 헤더 노드 바로 뒤의 첫 번째 노드를 가리키게 설계한다
노드 구조체 정의:
struct Node;
typedef struct Node *PtrToNode;
typedef PtrToNode Stack; // 스택은 결국 헤더 노드를 가리키는 포인터
struct Node {
ElementType Element; // 데이터 저장
PtrToNode Next; // 다음 노드 주소
};
주요 연산 및 조건
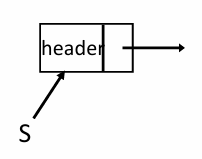
CreateStack
스택 생성및 초기화를 한다. 메모리에 헤더 노드를 위한 공간을 만들고, 초기 상태인 NULL로 설정한다
Stack CreateStack() {
Stack S;
S = malloc(sizeof(struct Node)); // 헤더 노드 생성
if (S == NULL) FatalError("메모리 부족!");
S->Next = NULL; // 처음엔 비어 있음
return S;
}
MakeEmpty
스택을 비운다. 스택에 데이터가 남아있다면, 비어있을 때까지 Pop 연산을 반복하여 메모리를 해제한다
void MakeEmpty(Stack S){
if (S==NULL)
Error("No stack exists");
else
while(!IsEmpty(S))
Pop(S);
}
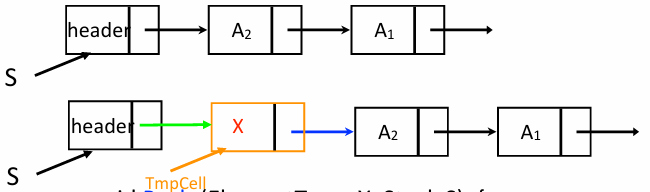
Push 데이터를 삽입한다. 새로운 노드를 생성하여 헤더 노드 바로 뒤에 끼워 넣는다. 이렇게 하면 삽입 연산이 항상 의 시간 복잡도를 가진다
- 삽입 과정
- 새 노드(TmpCell)를 위한 메모리를 할당한다
- 데이터 X를 저장한다
- 연결:
TmpCell의 다음이 현재 스택의 첫 번째 노드를 가리키게 한다 (TmpCell->Next = S->Next) - 헤더 갱신: 헤더가 이제 새 노드를 가리키게 한다 (
S->Next = TmpCell)
/* 요소 X를 스택 S에 삽입하는 함수 */
void Push(ElementType X, Stack S) {
PtrToNode TmpCell; // 1. 새 노드를 가리킬 임시 포인터 변수 선언
// 2. 메모리 할당: 새 노드가 들어갈 공간을 메모리에 만듭니다.
TmpCell = malloc(sizeof(struct Node));
// 3. 방어 코드: 메모리가 부족하여 할당에 실패했는지 확인합니다.
if (TmpCell == NULL) {
FatalError("Out of space!!!");
}
else {
// 4. 데이터 저장: 새 노드의 데이터 칸에 X를 넣습니다.
TmpCell->Element = X;
// 5. 연결 고리 만들기 (★핵심 단계 1)
// 새 노드의 다음(Next)이 원래 헤더가 가리키던 첫 번째 노드(S->Next)를 가리키게 합니다.
TmpCell->Next = S->Next;
// 6. 헤더 갱신 (★핵심 단계 2)
// 이제 헤더 노드(S)의 다음이 새 노드(TmpCell)를 가리키게 합니다.
S->Next = TmpCell;
}
}
Top 데이터를 확인한다. 현재 스택의 가장 위에 있는 데이터를 삭제하지 않고 읽기만 한다
ElementType Top(Stack S) {
if (!IsEmpty(S))
return S->Next->Element; // 첫 번째 노드의 데이터 반환
Error("스택이 비어있습니다");
return 0;
}
Pop 데이터를 추출하고 삭제한다. 가장 위에 있는 노드를 리스트에서 분리하고 메모리를 해제한다
- 삭제 과정
- 비어있는지 확인한다
- 첫 번째 노드를 임시 변수
FirstCell에 저장한다 - 헤더가 두 번째 노드를 가리키도록 연결을 우회시킨다(
S->Next = S->Next->Next) - 임시 변수에 저장했던 노드의 메모리를 해제한다
void Pop(Stack S) {
PtrToNode FirstCell; // 삭제할 노드를 임시로 가리킬 포인터
ElementType retVal; // 삭제할 노드에 담긴 값을 저장할 변수
// 1. 방어 코드: 스택이 비어있는지 먼저 확인
if (IsEmpty(S)) {
Error("Empty stack");
}
else {
// 2. 삭제할 노드 지정
// 헤더(S)가 가리키는 첫 번째 노드(Top)를 FirstCell에 저장합니다.
FirstCell = S->Next;
// 3. 데이터 복사
// 노드를 지우기 전에 그 안에 든 값(Element)을 따로 보관합니다.
retVal = FirstCell->Element;
// 4. 우회 연결 (Bypass) ★가장 중요
// 헤더가 이제 첫 번째 노드가 아닌, '두 번째 노드'를 가리키게 합니다.
// 이 과정에서 첫 번째 노드(A2)는 리스트 연결에서 떨어져 나옵니다.
S->Next = S->Next->Next;
// 5. 메모리 해제
// 리스트에서 고립된 노드의 메모리를 시스템에 반납합니다 (메모리 누수 방지).
free(FirstCell);
// 6. 값 반환
return retVal;
}
}
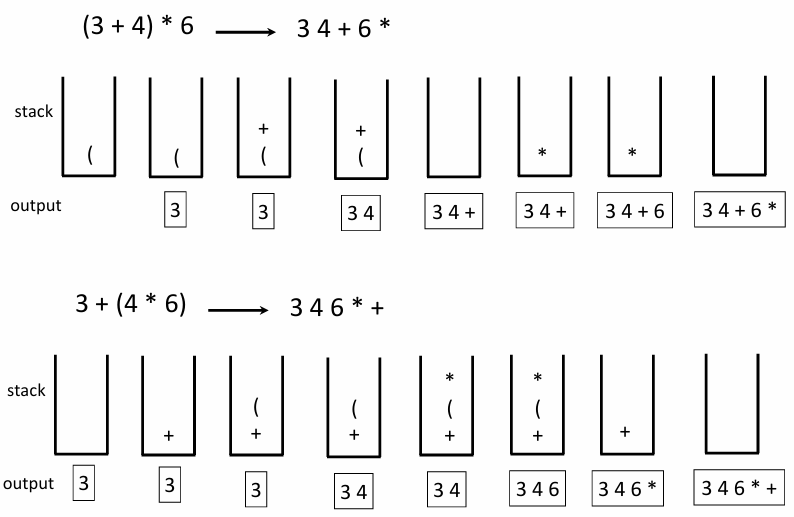
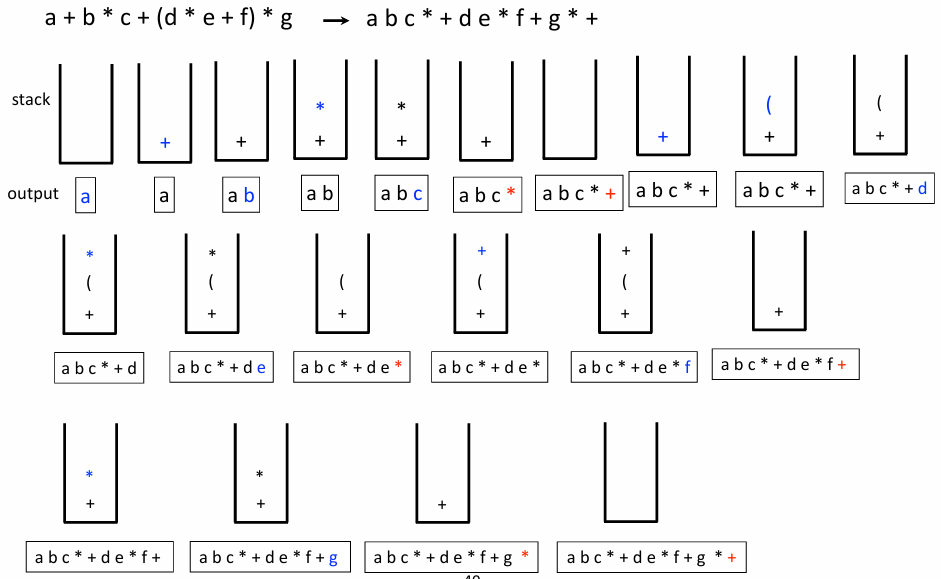
수식 표기법(Infix, Prefix, Postfix)
평소에 쓰는 수식은 위치에 따라 세 가지로 나눌 수 있다
중위 표기법(Infix Notation):
- 특징: 연산자가 피연산자 사이에 위치한다(예: )
- 문제점: 과 같은 식에서 를 먼저 할지, 을 먼저 할지 모호성(Ambiguity)이 발생한다. 이를 해결하기 위해 연산자 우선순위나 괄호가 반드시 필요한다
전위 표기법(Prefix Notation):
- 특징: 연산자가 피연산자 앞에 위치한다(예: )
- 예시:
* + 3 4 6+ 3 * 4 6
후위 표기법(Postfix Notation):
- 특징: 연산자가 피연산자 뒤에 위치한다(예: )
- 장점: 전위 표기법과 마찬가지로 괄호가 없어도 계산 순서가 명확하다. 컴퓨터(스택 자료구조)가 계산하기에 가장 효율적인 방식이다
- 예시:
3 4 + 6 *3 4 6 * +
후위 표기법의 계산 과정

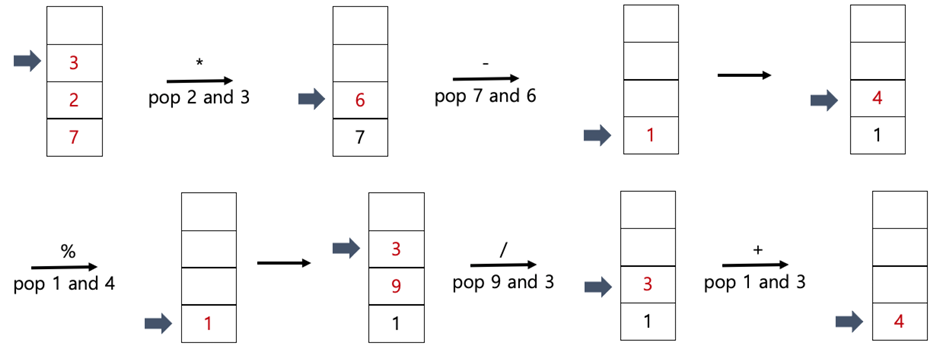
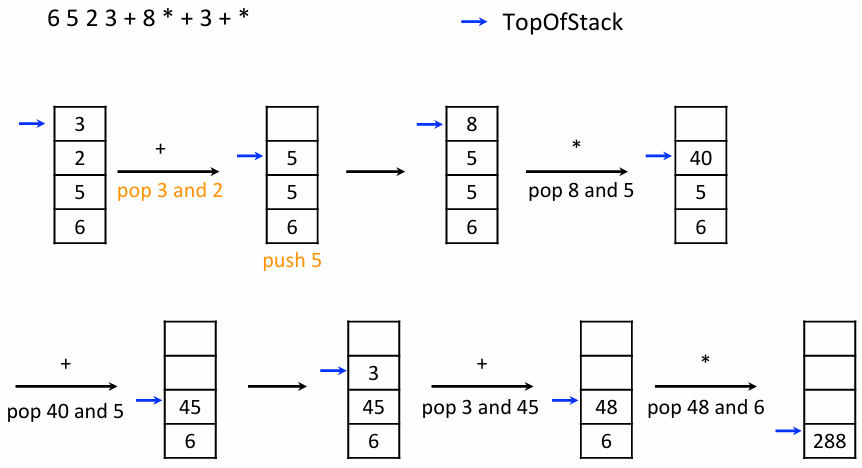
계산 규칙 컴퓨터는 스택을 사용하여 후위 표기식을 왼쪽에서 오른쪽으로 읽으며 계산한다
- 왼쪽에서 오른쪽으로 한 글자씩 스캔한다
- 피연산자(Operand, 숫자)를 만나면 스택에 넣는다
Push - 연산자를 만나면
- 스택에서 숫자 두 개를 꺼낸다
- 먼저 꺼낸 숫자가 오른쪽, 나중에 꺼낸 숫자가 왼쪽 피연산자가 되도록 계산한다
- 계산 결과 값을 다시 스택에 넣는다
계산 예시
**
중위에서 후워 변환 알고리즘(Stack 활용)
수식을 왼쪽에서 오른쪽으로 한 글자씩 읽으며 다음 규칙을 따른다
- 피연산자(Operand, 숫자/문자)를 만나면 즉시 출력한다
- 연산자(Operator)를 만나면
- 스택이 비어있으면
Push한다 - 스택이 비어있지 않다면, 스택의 Top에 있는 연산자와 우선순위를 비교한다
- 우선순위가 더 높은 연산자가 들어올 때만
Push한다 - 그렇지 않으면(들어오는 연산자 Top 연산자), 스택에서 연산자를 꺼내(
Pop) 출력하고 다시 비교한다
- 스택이 비어있으면
- 괄호를 만나면
- 왼쪽 괄호
(: 우선순위가 가장 높은 것으로 간주하여 무조건 스택에Push한다 - 오른쪽 괄호
): 왼쪽 괄호(가 나올 때까지 스택의 모든 연산자를Pop하여 출력한다(괄호 자체는 출력하지 않는다)
- 왼쪽 괄호
- 수식이 끝나면 스택에 남아있는 모든 연산자를 순서대로
Pop하여 출력한다
예시