리스트 ADT
리스트
리스트는 데이터들을 순서대로 나열한 자료구조이다
요소들의 순차적 서열:
- 리스트의 크기는 이다
- 크기가 0인 리스트는 빈 리스트이다
- 은 의 다음(후속) 요소이며, 은 의 이전 요소이다
- 요소 의 리스트 내 위치는 이다 ()
주요 연산
MakeEmpty(): 생성자. 빈 리스트를 반환한다DeleteList(List L): 소멸자. 리스트를 삭제한다Find(List L, Key K): 리스트 에서 값 가 있는 위치를 반환한다Insert(Key K, List L, Position P): 리스트 의 위치 다음에 값 를 삽입한다Delete(Key K, List L): 리스트 에서 값 를 삭제한다Concat(List L1, List L2): 두 리스트 과 를 하나로 연결하여 반환한다
예시: 리스트
Find(L, 52): 값 52는 3번째 위치에 있으므로 3을 반환한다Insert(X, L, 3): 3번째 위치(52) 뒤에 X를 삽입한다- 결과:
Delete(52, L): 리스트에서 값 52를 삭제한다- 결과:
배열 구현의 비효율성
배열을 이용한 리스트 구현은 다음과 같은 이유로 비효율적이다
크기 제한 및 메모리 낭비
- 리스트의 최대 크기를 미리 예상해서 정해야 한다
- 이 과정에서 실제로 필요한 것보다 더 많은 저장 공간을 할당하게 되어 메모리 낭비가 발생한다
삽입 및 삭제의 높은 비용
- 리스트의 앞부분이나 중간에 데이터를 삽입/삭제하는 것이 어렵다. 데이터를 계속 뒤로 밀거나 앞으로 당겨야 하기 때문이다
- 최악의 경우(Worst case):
- 평균적인 경우(Average case): 리스트의 절반을 이동시켜야 하므로
- 개의 요소를 연속해서 삽입하여 리스트를 만들 경우: 의 시간이 소요된다
연결 리스트(Linked list) 구현의 특징
연결 리스트의 정의
연결 리스트는 데이터를 한 줄로 늘어세우되, 물리적인 메모리 위치에 구애받지 않는 유연한 구조이다
메모리 비연속성: 연결 리스트를 구성하는 구조체(노드)들은 메모리상에서 반드시 인접해 있을 필요가 없다
노드의 구성: 각 노드는 실제 데이터인 요소(element)와 다음 노드를 가리키는 포인터로 구성된다
리스트의 끝: 가장 마지막 노드의 포인터는 아무것도 가리키지 않는 NULL을 가리켜 끝임을 나타낸다

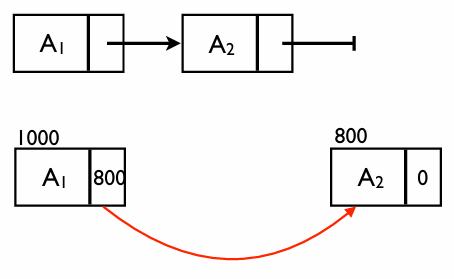
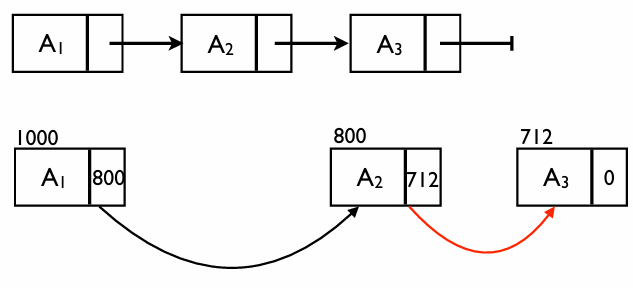
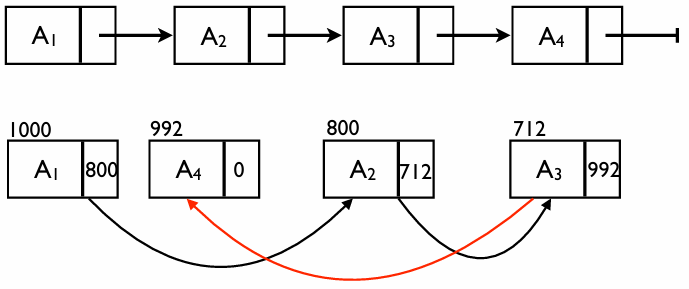
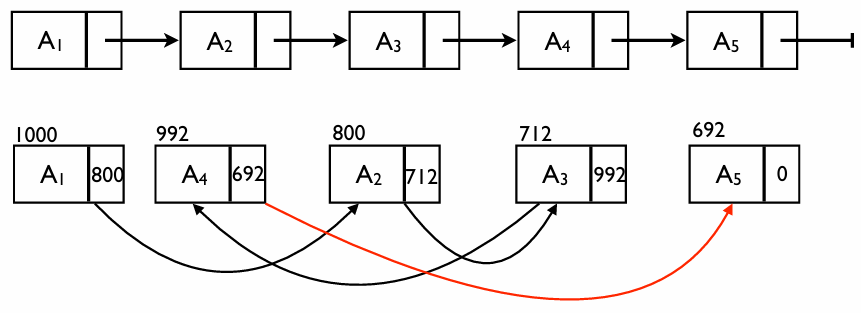
메모리 할당의 예시
배열은 메모리가 붙어 있어야 하지만, 연결 리스트는 빈 공간 어디든 들어갈 수 있다
C언어를 이용한 구현
구조체 정의 먼저 노드의 형태를 정의해야 한다. 데이터와 다음 노드의 주소를 담을 포인터가 필요하다
typedef struct listNode *listPointer; // 노드를 가리키는 포인터 타입 정의
typedef struct listNode {
int data; // 데이터를 저장할 변수
listPointer link; // 다음 노드를 가리키는 포인터 (자기 참조 구조체)
} node;실행 예시: main 함수 로직 두 개의 노드를 만들어 서로 연결하는 과정이다
int main() {
// 1. 노드를 가리킬 포인터 변수 선언
listPointer first, second;
// 2. 메모리 동적 할당: 실제 노드가 들어갈 공간을 메모리(Heap)에 생성
// (node*)malloc(sizeof(node))는 "노드 크기만큼 땅을 빌려와라"라는 뜻입니다.
first = (node*)malloc(sizeof(node));
second = (node*)malloc(sizeof(node));
// 3. 두 번째 노드 설정
second->data = 20; // 데이터로 20을 저장
second->link = NULL; // 이 노드가 마지막이므로 가리킬 다음 주소는 없음(NULL)
// 4. 첫 번째 노드 설정 및 연결
first->data = 10; // 데이터로 10을 저장
first->link = second; // ★중요: 첫 번째 노드의 링크가 두 번째 노드의 주소를 가리키게 함
// [이 시점에서 리스트의 형태: [10] -> [20] -> NULL]
// 5. 메모리 해제: 빌려 쓴 메모리를 시스템에 반납 (C언어의 필수 과정)
free(first);
free(second);
return 0;
}삽입(insertion)
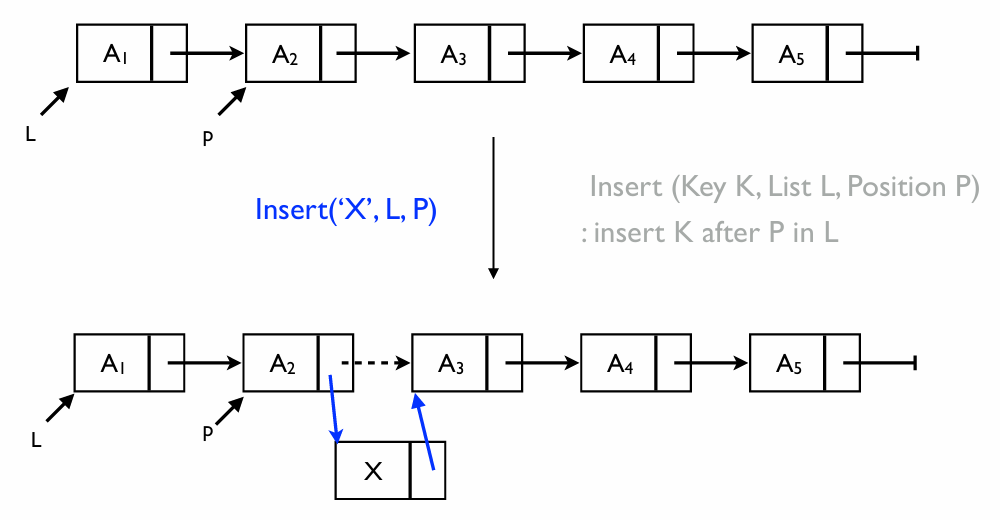
연결 리스트에서 새로운 노드를 삽입하는 것은 기존의 연결 고리를 끊고 새로운 노드를 사이에 끼워 넣는 과정이다
삽입 연산: Insert('X', L, P)
- 의미: 리스트 L의 위치P 다음에 새로운 값 X를 삽입한다
삭제(deletion)
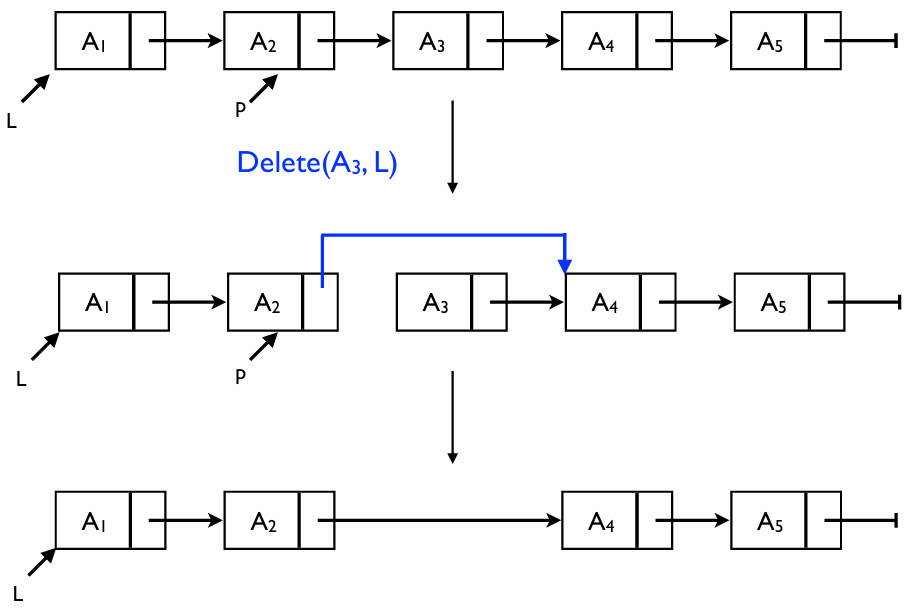
삭제는 삭제하려는 노드를 건너뛰도록 연결 고리를 재설정하는 과정이다
삭제 연산: Delete(A3, L)
- 의미: 리스트 L에서 요소 를 삭제한다
연결 리스트를 위한 타입 선언
연결 리스트를 구성하는 노드와 포인터 타입을 정의하는 단계이다
typedef struct Node* PtrToNode; // 노드를 가리키는 포인터 타입을 PtrToNode로 정의
typedef PtrToNode Position; // 위치를 나타내는 타입 (결국 노드 포인터)
typedef PtrToNode List; // 리스트 자체를 나타내는 타입
typedef int ElementType; // 데이터의 타입 (여기서는 정수형)
struct Node {
ElementType Element; // 데이터를 저장하는 변수
Position Next; // 다음 노드를 가리키는 포인터
};- 주요 함수
List MakeEmpty(): 빈 리스트를 생성한다int IsEmpty(List L): 리스트가 비어있는지 확인한다int IsLast(Position P, List L): 특정 위치 가 리스트의 마지막인지 확인한다Position Find(ElementType X, List L): 값 가 있는 위치를 찾는다Position FindPrevious(ElementType X, List L): 값 의 이전 노드 위치를 찾는다void Delete(ElementType X, List L): 값 를 찾아 삭제한다void Insert(ElementType X, List L, Position P): 위치 다음에 를 삽입한다void DeleteList(List L): 리스트 전체를 삭제한다
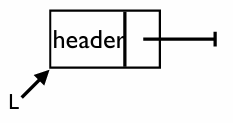
MakeEmpty: 빈 리스트 생성
이 구현에서는 헤더 노드라는 특별한 노드를 사용한다. 헤더 노드는 실제 데이터를 저장하지 않고, 리스트의 시작점 역할을 수행하여 삽입, 삭제 로직을 단순하게 만들어 준다
코드 분석
/* 헤더 노드를 생성합니다 */
List MakeEmpty() {
List L;
// 노드 크기만큼 메모리를 할당하고 L에 저장
L = (List)malloc(sizeof(struct Node));
L->Element = header; // (선택사항) 헤더 노드임을 표시
L->Next = NULL; // 다음 노드가 없으므로 NULL로 초기화
return L;
}
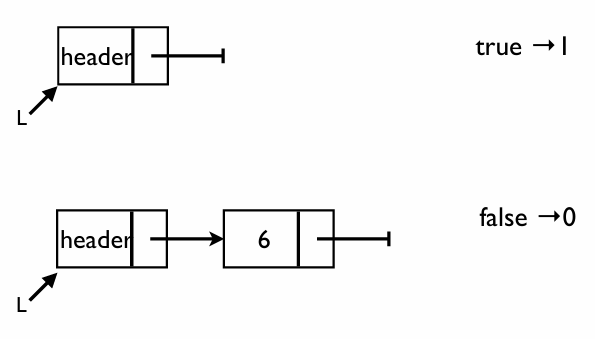
IsEmpty: 리스트가 비어있는지 확인
리스트가 비어있다는 것은 헤더 노드 뒤에 연결된 실제 데이터 노드가 하나도 없다는 뜻이다
로직 판단
- 비어있을 때(True):
L (header) -> NULL- 결과값: 1 (True) 반환
- 비어있지 않을 때 (False):
L (header) -> [6] -> NULL- 결과값: 0 (False) 반환
코드 분석
/* 리스트 L이 비어있으면 true를 반환합니다 */
int IsEmpty(List L) {
return L->Next == NULL;
}
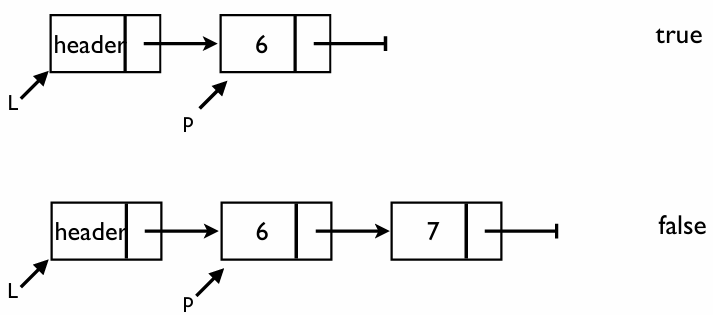
IsLast: 해당 노드가 마지막인지 확인
이 함수는 특정 위치가 리스트의 가장 끝 노드인지 판별한다
핵심 로직
연결 리스트의 마지막 노드는 다음 노드를 가리키는 Next 포인터가 NULL이라는 특징을 이용한다
코드 분석
/* P가 리스트 L의 마지막 위치이면 true(1)를 반환합니다 */
int IsLast(Position P, List L) {
return P->Next == NULL;
}
Find: 특정 요소 찾기
리스트 에서 데이터 를 가진 노드를 찾아 그 위치(Position)를 반환하는 함수이다
검색 과정
- 시작점 설정: 헤더 노드는 실제 데이터가 아니므로, 첫 번째 데이터 노드인 **
L->Next**부터 검색을 시작한다(P = L->Next) - 반복 탐색: 다음 두 조건 중 하나라도 만족할 때까지 옆 노드로 계속 이동한다
P == NULL: 리스트의 끝까지 갔으나 데이터를 못 찾은 경우P->Element == X: 원하는 데이터를 찾은 경우
- 결과 반환: 찾았다면 해당 노드의 주소를, 못 찾았다면
NULL을 반환한다
코드 분석
/* L에서 X의 위치를 반환합니다. 찾지 못하면 NULL을 반환합니다. */
Position Find(ElementType X, List L) {
Position P;
// 1. 첫 번째 요소(헤더 다음 노드)부터 시작
P = L->Next;
// 2. P가 NULL이 아니고(끝이 아니고), 찾는 값이 아닐 동안 계속 이동
while (P != NULL && P->Element != X) {
P = P->Next;
}
// 3. 찾은 위치(또는 끝까지 가서 NULL이 된 P)를 반환
return P;
}
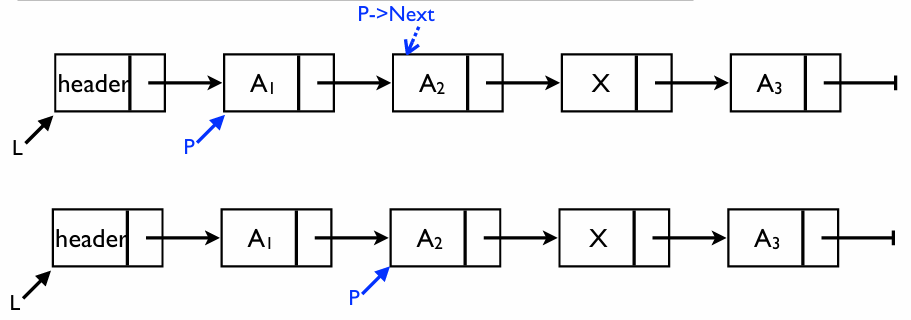
FindPrevious: 특정 값의 이전 노드 찾기
연결 리스트는 뒤로만 갈 수 있기 때문에, 어떤 노드를 삭제하려면 반드시 그 앞의 노드를 알고 있어야 한다
핵심 로직
현재 내 위치 가 아니라, 내 다음 노드(P->Next)에 내가 찾는 값( 이 있는지 확인하며 전진한다
- 시작점: 헤더 노드부터 시작한다
- 반복 조건:
- 다음 노드가 존재해야 함 (
P->Next != NULL) - 다음 노드의 값이 내가 찾는 값이 아니어야 함 (
P->Next->Element != X)
- 다음 노드가 존재해야 함 (
- 결과: 위 조건을 만족하지 않아 루프를 빠져나오면,
P는X를 가진 노드의 직전 노드가 된다
코드 분석
/* 요소 X의 이전 노드 위치를 반환합니다. */
Position FindPrevious(ElementType X, List L) {
Position P;
P = L; // 헤더부터 시작
// 다음 노드가 있고, 그 노드의 데이터가 X가 아닐 동안 옆으로 이동
while (P->Next != NULL && P->Next->Element != X) {
P = P->Next;
}
return P; // X 직전의 위치를 반환
}
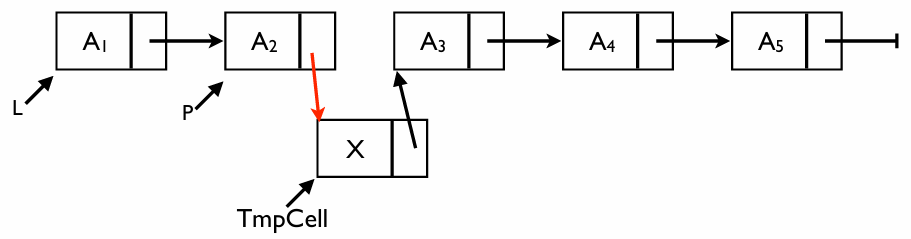
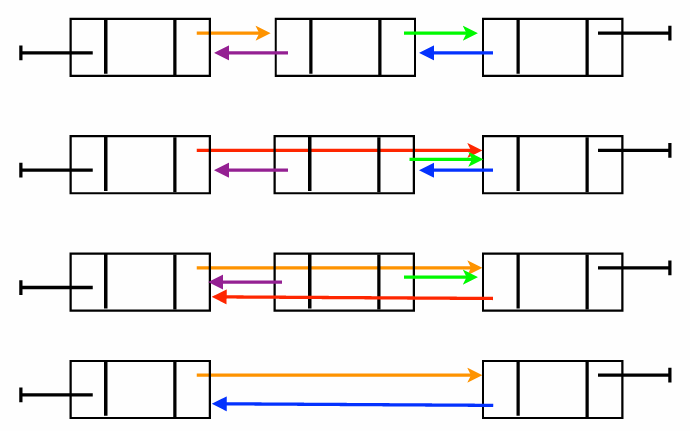
Insert: 새로운 데이터 삽입하기
특정 위치 바로 다음에 새로운 값 를 끼워 넣는 과정이다
삽입의 4단계
- 메모리 할당: 새 노드(
TmpCell)를 위한 공간을 만든다 - 데이터 저장:
TmpCell에 값 를 넣는다 - 새 노드 연결:
TmpCell의 다음 화살표가 원래 가 가리키던 노드를 가리키게 한다 - 이전 노드 재연결: 이제 의 화살표를
TmpCell로 향하게 바꾼다
코드 분석
/* 위치 P 다음에 요소 X를 삽입합니다. */
void Insert(ElementType X, List L, Position P) {
Position TmpCell;
// 1. 메모리 할당 및 에러 체크
TmpCell = malloc(sizeof(struct Node));
if (TmpCell == NULL) {
FatalError("메모리 공간이 부족합니다!!!");
}
// 2. 값 대입
TmpCell->Element = X;
// 3. 연결 고리 만들기 (★순서가 매우 중요합니다)
TmpCell->Next = P->Next; // 새 노드가 P의 뒷사람을 먼저 가리킴
P->Next = TmpCell; // P가 이제 새 노드를 가리킴
}
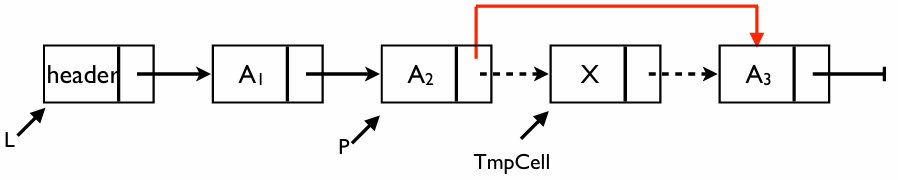
Delete: 특정 값을 삭제하기
리스트 에서 특정 값 를 찾아 삭제하는 함수이다. 연결 리스트에서는 삭제하려는 노드의 이전 노드를 반드시 알아야한다
핵심 로직
- 이전 노드 찾기:
FindPrevious함수를 사용하여 삭제할 값 가 담긴 노드의 바로 앞 위치를 찾는다 - 존재 확인: 만약 가 리스트의 마지막이 아니라면(
!IsLast(P, L)), 이는 가 리스트에 존재한다는 뜻이다 - 우회 연결 (Bypass): 의 다음 노드를 노드의 다음 노드로 직접 연결한다
- 메모리 해제: 이제 리스트에서 분리된 노드의 메모리를
free를 통해 시스템에 반납한다
코드 분석
/* 리스트 L에서 요소 X의 첫 번째 출현을 삭제합니다. */
void Delete(ElementType X, List L) {
Position P, TmpCell;
// 1. 삭제할 노드의 '이전 노드'를 찾습니다.
P = FindPrevious(X, L);
// 2. X가 발견되었는지 확인 (P가 마지막 노드라면 X가 없는 것)
if (!IsLast(P, L)) {
// 3. 삭제할 노드(TmpCell)를 지정합니다.
TmpCell = P->Next;
// 4. 우회 연결: P의 Next가 삭제할 노드의 Next를 가리키게 합니다.
// 이 과정에서 TmpCell(X 노드)은 리스트에서 고립됩니다.
P->Next = TmpCell->Next;
// 5. 메모리 해제: 고립된 노드를 삭제하여 메모리 누수를 방지합니다.
free(TmpCell);
}
}
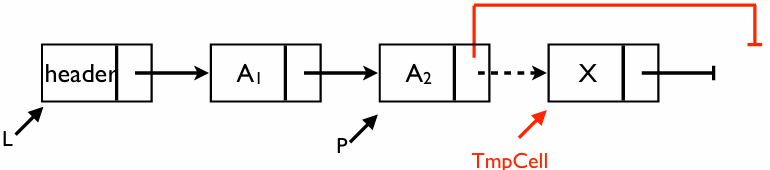
FindPrevious 재확인
Delete 연산을 성공시키기 위해 가장 중요한 보조 함수이다
- 역할: 요소 를 포함하는 노드의 직전 위치를 찾아 반환한다
- 데이터를 찾으면 해당 데이터의 앞 노드 주소를 반환한다
- 데이터를 찾지 못하면 리스트의 가장 마지막 노드 주소를 반환하게 된다(이 경우
IsLast(P, L)가 참이 되어 삭제가 수행되지 않는다)
- 데이터를 찾지 못하면 리스트의 가장 마지막 노드 주소를 반환하게 된다(이 경우
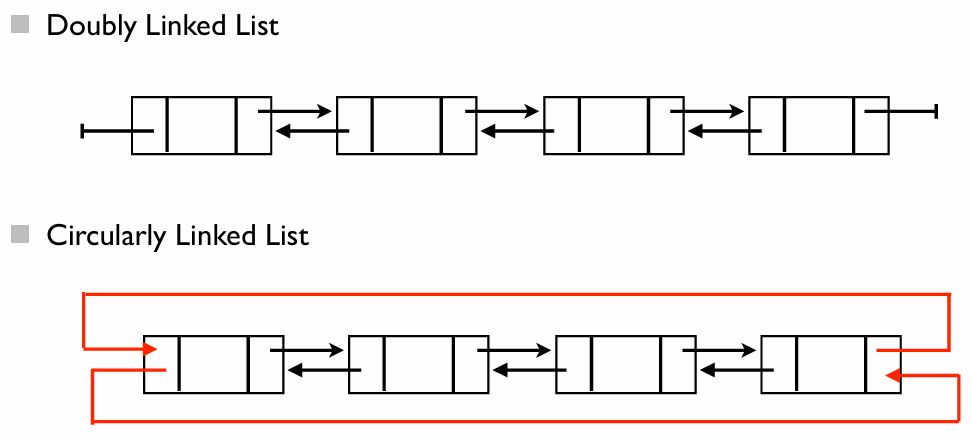
이중 연결 리스트(Doubly Linked List)
단일 연결 리스트와 달리, 각 노드는 앞과 뒤를 모두 알고 있다
노드의 구성 요소
struct Node{
ElementType Element; //실제 저장할 데이터
Position Next; //다음 노드를 가리키는 포인터
Position Prev; //이전 노드를 가리키는 포인터
};
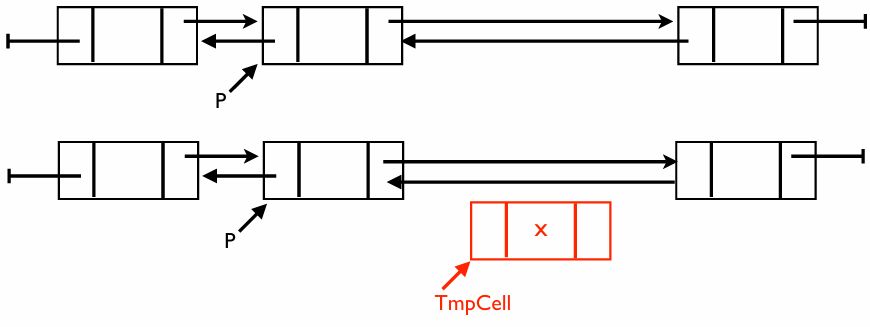
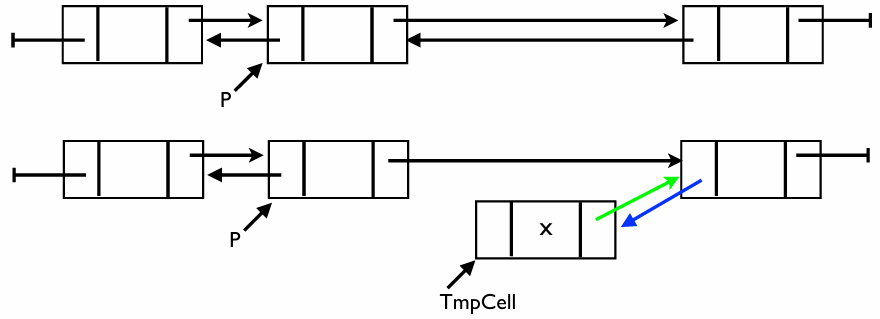
삽입 연산
Position P 바로 다음에 데이터 를 가진 새 노드(TmpCell)를 삽입하는 과정이다
핵심 로직
- 메모리 할당 및 데이터 저장: 먼저 새 노드를 만들고 값을 채워 넣는다
- 오른쪽 연결: 이미 연결된 기차 칸 사이에 들어가기 위해, 먼저 뒤쪽 노드와 손을 잡는다
- 왼쪽 연결: 이제 앞쪽 노드와 서로의 주소를 교환한다
코드 분석
void Insert(ElementType X, List L, Position P) {
Position TmpCell;
TmpCell = malloc(sizeof(struct Node)); // 새 노드 공간 확보
if (TmpCell == NULL)
FatalError("Out of space!!!"); // 메모리 부족 시 에러 처리
TmpCell->Element = X; // 데이터 'X' 저장
TmpCell->Next = P->Next; // 새 노드의 다음은 P의 원래 다음 노드
TmpCell->Next->Prev = TmpCell; // P의 다음 노드의 이전은 이제 새 노드
P->Next = TmpCell; // P의 다음은 이제 새 노드
TmpCell->Prev = P; // 새 노드의 이전은 P
}
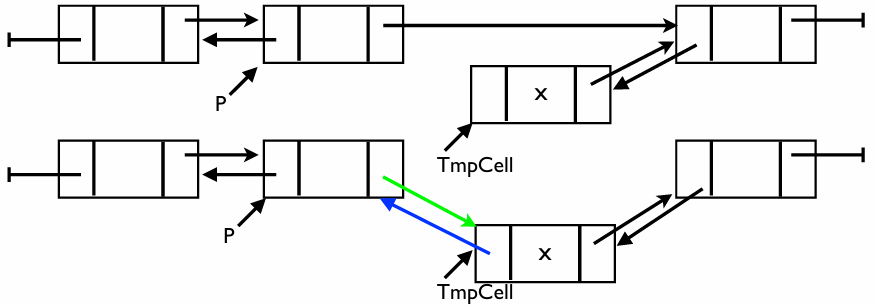
삭제 연산
이중 연결 리스트에서 노드를 삭제하는 과정은 삭제할 노드를 기준으로 앞 노드와 뒷 노드를 직접 연결하여 를 고립시키는 과정이다
핵심 로직
단일 연결 리스트와 달리, 이중 연결 리스트는 각 노드가 Prev 포인터를 가지고 있어 삭제할 노드만 알면 앞뒤 노드에 즉시 접근할 수 있다
- 앞 노드의 Next 수정: 의 이전 노드가 의 다음 노드를 가리키게 한다
- 뒷 노드의 Prev 수정: 의 다음 노드가 의 이전 노드를 가리키게 한다
- 메모리 해제: 리스트에서 완전히 분리된 를 메모리에서 제거한다
코드 분석
void Delete(ElementType X, List L) {
Position P;
// 1. 삭제할 데이터 X가 있는 노드 P를 찾습니다.
P = Find(X, L);
if (P != NULL) {
// 2. 앞 노드의 Next를 뒷 노드로 연결 (P 건너뛰기)
P->Prev->Next = P->Next;
// 3. 뒷 노드의 Prev를 앞 노드로 연결 (P 건너뛰기)
P->Next->Prev = P->Prev;
// 4. 고립된 노드 P의 메모리를 반납합니다.
free(P);
}
}
원형 연결 리스트
원형 연결 리스트는 리스트의 마지막 노드와 첫 번째 노드가 서로 연결되어 원 형태를 이루는 구조이다
특징 및 구조
- 끝이 없는 구조: 일반적인 리스트는 끝 노드의
Next가NULL이지만, 원형 리스트는 다시 처음으로 돌아간다 - 이중 원형 연결 리스트: PPT 예시처럼 이중 연결 리스트를 원형으로 만들면 다음과 같은 연결이 추가된다
- 마지막 노드의 Next 첫 번째 노드(헤더)
- 첫 번째 노드의 Prev 마지막 노드