분류 vs. 예측
가장 먼저 이 두 개념의 차이를 명확히 아는 것이 중요하다
| 구분 | 분류 (Classification) | 예측 (Prediction) |
|---|---|---|
| 대상 | 범주형(Categorical) 클래스 라벨 | 연속적인 값(Continuous-valued) |
| 특징 | 데이터가 어느 그룹(A 또는 B)에 속하는지 판단 | 알려지지 않았거나 누락된 수치를 추정 |
| 모델 | 훈련 데이터를 학습하여 모델 구축 | 수치형 함수를 모델링함 |
| 주요 응용 분야: 신용 승인, 의료 진단, 사기 감지 등 |
분류의 과정: 2단계 프로세스
분류는 크게 모델 구축(Learning)과 모델 사용(Teasting)의 두 단계를 거친다
Step 1: 모델 구축 (Model Construction)
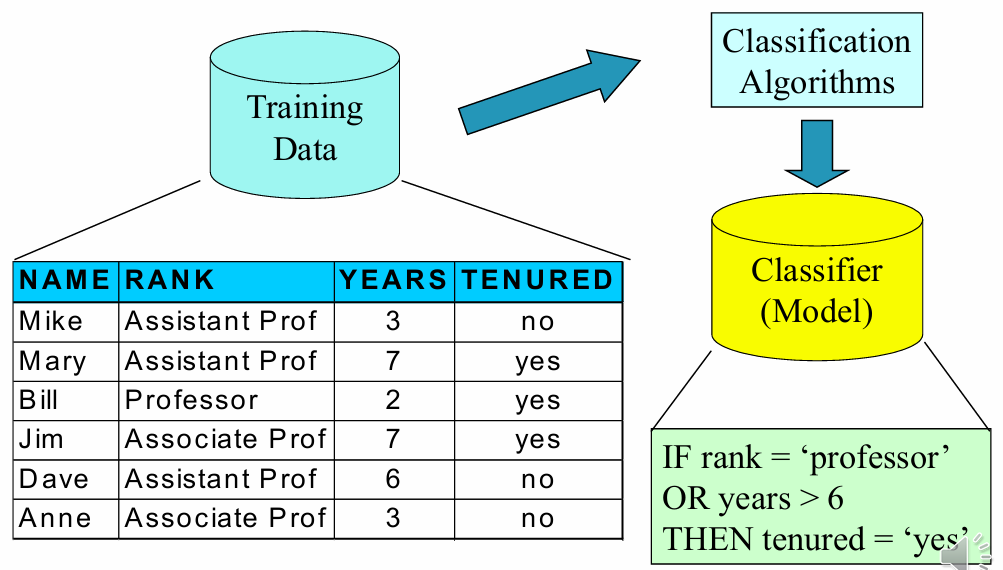
- 목표: 훈련 데이터를 사용하여 미리 정의된 클래스들을 설명하는 모델을 만든다
- 훈련 데이터: 각 샘플은 여러 속성()과 클래스 라벨(Class label)로 구성된다
- 결과물: 모델은 분류 규칙, 의사결정나무, 신경망 또는 수학적 공식 형태로 표현한다
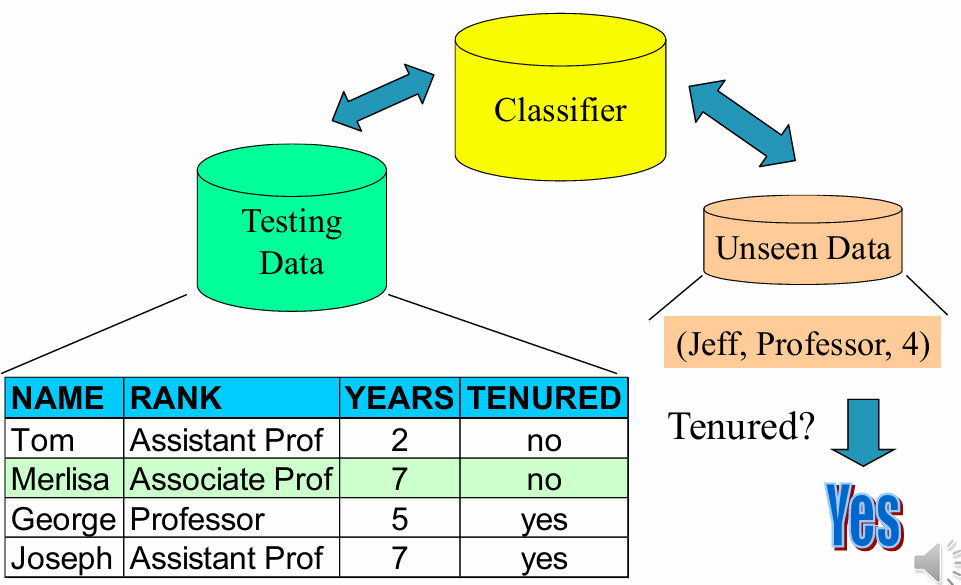
Step 2: 모델 사용 및 정확도 평가 (Model Usage & Evaluation)
- 정확도 평가 (Accuracy evaluation):
- 테스트 데이터: 모델 구축에 사용되지 않은 독립적인 데이터를 사용해야 한다
- 오버피팅(Over-fitting): 테스트 세트와 훈련 세트가 겹치면 정확도가 과하게 높게 나오는 현상이 발생하므로 주의해야 한다
- 정확도(Accuracy rate): 테스트 세트 샘플 중 모델이 올바르게 분류한 비율이다
- 실제 분류: 정확도가 허용 가능한 수준이라면, 라벨을 모르는 새로운 데이터를 분류하는 데 모델을 사용한다
프로세스
모델 구축 데이터로부터 규칙을 찾아내어 분류기를 만드는 단계이다
모델을 사용한 예측 만들어진 모델이 얼마나 정확한지 확인하고, 새로운 데이터를 판별하는 단계이다
지도 학습 vs. 비지도 학습
데이터 마이닝의 가장 핵심적인 두 갈래를 비교한다
지도 학습(Supervised Learning - 분류) 정답(Label)이 있는 데이터를 학습한다. 각 관측치에 클래스 라벨이 붙어 있으며, 모델은 이 라벨을 맞히는 방향으로 학습한다. 목표는 훈련 세트를 기반으로 새로운 데이터의 클래스를 분류한다
비지도 학습(Unsupervised Learning - 군집화) 정답(Label)이 없는 데이터를 학습한다. 데이터의 클래스 라벨을 모르는 상태에서, 데이터 간의 유사성이나 측정값만을 이용한다. 목표는 데이터 내에 존재하는 자연스러운 그룹이나 구조를 스스로 찾아내는 것이다
이슈: 데이터 준비(Data Preparation)
좋은 모델은 좋은 데이터에서 나온다. 학습 전 데이터를 정제하는 3가지 핵심 단계이다
데이터 정제(Data cleaning):
- 데이터의 노이즈를 줄이고 결측치(Missing values)를 처리하는 전처리 과정이다
관련성 분석(Relevance analysis - 특성 선택):
- 분류에 도움이 되지 않는 무관하거나 중복된 속성(Attrubutes)들을 제거하여 모델의 효율성을 높인다
데이터 변환(Data transformation):
- 데이터를 일반화하거나 정규화하여 모델이 학습하기 좋은 형태로 바꾼다
분류 방법의 평가 기준
모델을 만들었다면 다음의 기준들로 그 성능을 평가한다
정확도:
- 분류기 정확도: 클래스 라벨을 얼머나 잘 맞히는가
- 예측기 정확도: 수치 데이터를 얼마나 정확히 추정하는가
속도: 모델을 만드는 학습 시간과 실제 데이터를 분류하는 예측 시간을 모두 고려한다
강건성(Robustness): 노이즈나 결측치가 있는 불완전한 데이터에서도 얼마나 잘 견디고 성능을 유지하는지를 나타낸다
확장성 (Scalability): 대규모 데이터베이스에서도 효율적으로 작동하는 능력을 의미한다
해석 가능성 (Interpretability): 모델이 제공하는 결과가 얼마나 이해하기 쉽고 통찰력을 주는지를 평가한다
기타 측정치: 의사결정나무의 크기나 분류 규칙의 간결함 등도 고려 대상이다
의사결정나무 유도(Decision Tree Induction)
의사결정나무는 데이터에 숨겨진 규칙을 나무 모양의 도표로 만들어내는 기법이다
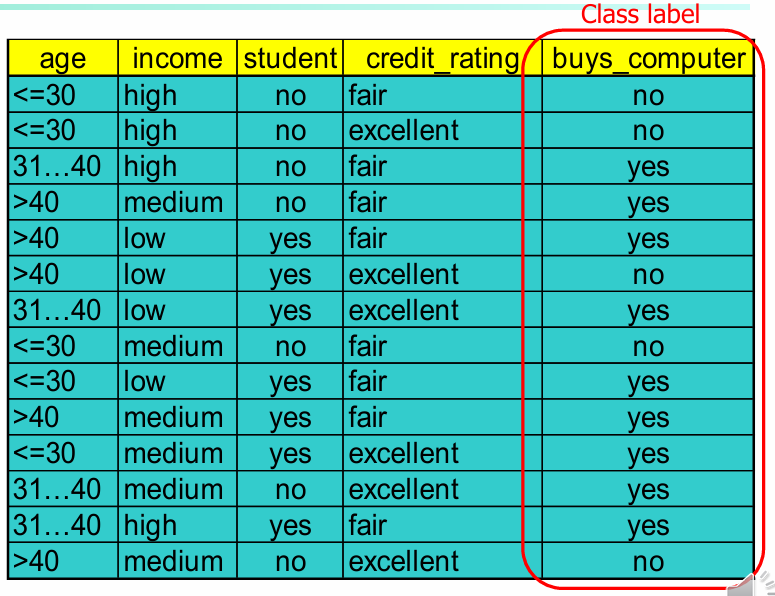
학습용 데이터셋 (Training Dataset)
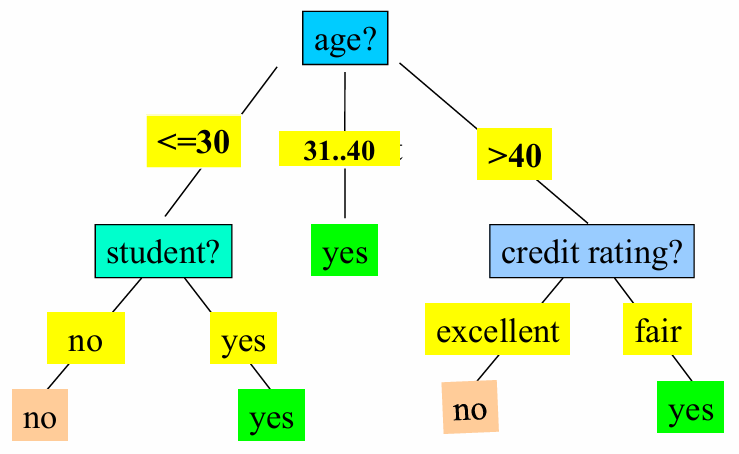
의사결정 나무의 구조(Output) 위의 데이터를 학습하여 만들어진 최종 결과물이다
의사결정나무 유도 알고리즘
컴퓨터가 어떻게 이 나무를 만드는지에 대한 원리이다
기본 알고리즘: 탐욕적 알고리즘(Greedy algorithm)을 사용한다
- 하향식(Top-down) 방식: 위에서 아래로 내려오며 나무를 만든다
- 재귀적 분할(Recursive divide-and-conquer): 데이터를 계속해서 더 작은 그룹으로 쪼개나가는 방식이다
속성 타입: 기본적으로 범주형 속성을 가정한다(수치형 데이터는 미리 범위를 나누어 이산화해야 한다)
핵심 기준(Heuristic): 어떤 속성을 먼저 물어볼지는 통계적 척도를 기준으로 정한다
- 가장 유명한 척도가 바로 정보 이득(Information Gain)이다
분할 중단 조건
트리를 무한정 키울 수는 없으므로, 데이터를 쪼개는 과정을 언제 멈출지 결정하는 3가지 기준이다
클래스 일치: 주어진 노드에 있는 모든 샘플이 동일한 클래스에 속할 때 분할을 멈춘다
속성 고갈: 더 이상 데이터를 나눌 수 있는 속성이 남아 있지 않을 때 멈춘다
- 이 경우, 해당 리프 노드에 있는 샘플 중 가장 많은 수를 차지하는 클래스로 분류하는 다수결 원칙을 적용한다
샘플 고갈: 분할된 결과 해당 노드에 더 이상 샘플이 남아 있지 않을 때 멈춘다
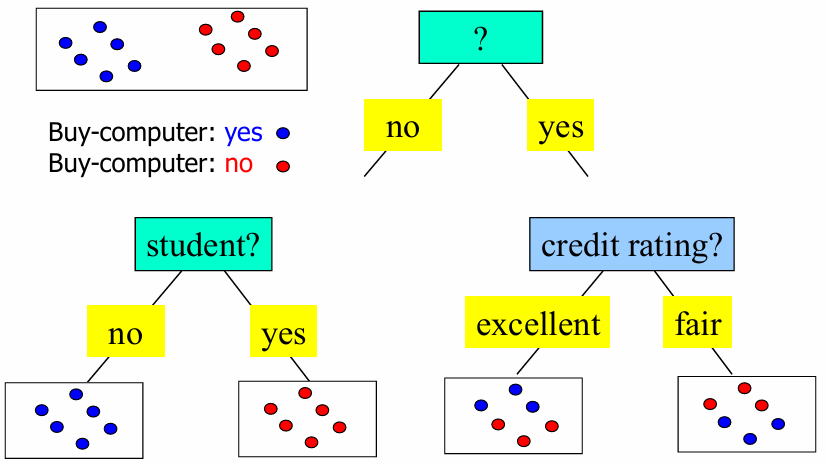
테스트 속성 선택
어떤 질문(속성)을 먼저 던지는 것이 가장 효율적인지 결정하는 단계이다
- 핵심 원리: 그룹을 분할했을 때 결과가 더 균질한(More homogeneous) 쪽을 선택한다
- 예시 분석: 그림을 보면 ‘student?’ 질문으로 나눴을 때와 ‘credit rating?‘으로 나눴을 때를 비교한다. 한쪽 방향으로 파란 점이나 빨간 점이 몰려 있는(즉, 섞이지 않고 정답이 확실해지는) 질문이 더 좋은 속성이다
속성 선택 척도: 정보 이득(Information Gain)
어떤 속성이 더 좋은지 수학적으로 계산하는 방법이다. 정보 이득이 가장 높은 속성을 선택이다
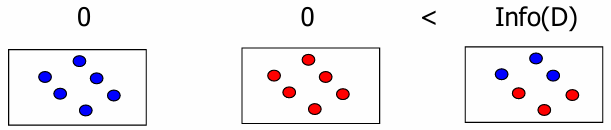
엔트로피(Entropy, 기대 정보량) 데이터가 얼마나 섞여 있는지(불확실성)를 측정하는 수치이다
- 수식:
- : 데이터셋 D에서 임의의 샘플이 클래스 에 속할 확률이다
- 성질: 데이터가 더 많이 섞여 있을수록(더 불균질할수록) 엔트로피 값은 높아진다
정보 이득 핵심 공식 정의: 속성 를 사용하여 데이터셋 를 개의 파티션으로 나누었을 때의 수식들이다
- 기대 정보량(): 속성 로 데이터를 나누었을 때, 여전히 분류를 위해 필요한 추가적인 정보량이다
- 정보 이득(): 원래의 혼란도()에서 분할 후의 혼란도()를 뺀 값이다. 즉, 이 질문을 함으로써 우리가 얻은 이득을 의미한다
예시
4명의 고객 데이터를 바탕으로 ‘나이(age)’ 속성의 정보 이득을 계산하는 과정이다
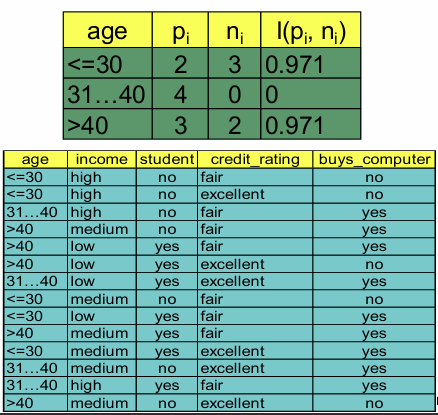
Step 1: 전체 데이터의 엔트로피 계산 전체 14명 중 구매자(Yes) 9명, 비구매자(No) 5명이다
- 현재 우리 데이터셋의 전체적인 혼란(불확실성)은 0.940이다
Step 2: ‘나이’로 나눈 후의 기대 정보량 계산 ‘나이’는 세 그룹(, , )으로 나뉜다
- : 5명 중 2명 Yes, 3명 No
- : 4명 중 4명 Yes, 0명 No
- : 5명 중 3명 Yes, 2명 No
이를 가중 평균하여 계산하면:
Step 3: ‘나이’의 정보 이득 도출
최종 결과 결정 다른 속성들의 정보 이득도 같은 방식으로 계산한 결과입니다:
- (가장 높음!)
- 결론: ‘나이’를 기준으로 데이터를 가르는 것이 가장 정보를 많이 얻는(혼란도를 많이 낮추는) 선택이므로, 루트 노드(Root Node)의 질문은 “나이가 어떻게 되나요?”가 된다
연속형 속성에 대한 정보 이득 계산(Computing Information-Gain for Continuous-Value Attributes)
의사결정나무는 연속형 속성 를 그대로 쓸 수 없기 때문에, 적절한 분할 지점(split points)을 찾아 데이터를 이산형(Discrete)으로 변환하는 과정을 거친다
분할 후보 지점 결정(Discretization)
- 데이터 정렬: 먼저 속성 의 기존 값들을 오름차순(increasing order)으로 정렬한다
- 중앙값 활용: 일반적으로 인접한 두 값 사이의 중앙값(midpoint)을 잠재적인 분할 지점 후보로 고려한다
- 공식: 와 사이의 중앙값은 이다
최적의 분할 지점 선택 모든 후보 지점에 대해 어떤 선이 가장 좋은지 테스트이다
- 엔트로피 계산: 각 분할 지점을 기준으로 데이터를 두 그룹으로 나눈다
- : 인 데이터 집합
- : 인 데이터 집합
- 최적 지점 결정: 여러 후보 중 엔트로피가 최소가 되는 지점(즉, 정보 이득이 최대가 되는 지점)을 최종 분할 지점으로 선택한다
이진 분할 vs. 다중 분할 (n-ary partition) 현재는 데이터를 두 개로만 나누는 이진 분할(binary partition)을 가정하고 있지만, 여러 구간으로 나누는 차 분할도 고려해 볼 수 있다
- 질문: 차 분할을 고려할 때 발생할 수 있는 문제점은 무엇일까?
- 오버피팅(Overfitting) 위험: 구간을 너무 세밀하게 나누면 훈련 데이터에만 너무 딱 맞는 모델이 되어, 새로운 데이터에 대한 예측력이 떨어질 수 있다
- 복잡도 증가: 계산해야 할 조합이 기하급수적으로 늘어나 연산 비용이 커진다
- 데이터 편향: 정보 이득 척도는 기본적으로 ‘값이 많은 속성’을 선호하는 경향이 있어, 무의미하게 구간이 많은 쪽이 선택될 가능성이 높다


정보 이득비(Gain Ratio - C4.5 알고리즘)
기존의 정보 이득(Information Gain)은 값이 너무 많은 속성을 선호하는 치명적인 편향(Bias)이 있다
왜 정보 이득비가 필요한가?
- 문제점: 예를 들어 속성 는 값이 개이고, 는 개라면 알고리즘은 의 정보 이득을 더 높게 평가하는 경향이 있다. 극단적으로 ‘고객 ID’처럼 모든 값이 고유하다면 정보 이득은 최대가 되지만, 실제 분류에는 아무런 도움이 되지 않는다
- 해결책: ID3의 후속인 C4.5 알고리즘은 정보 이득을 정규화(Normalization)한 정보 이득비를 사용한다
공식 및 계산
- : 속성 가 데이터를 얼마나 잘게 쪼개는지를 나타내는 척도이다
- 예시 (Income 속성):
- 결정 기준: 정보 이득비가 가장 큰(Maximum) 속성을 분할 기준으로 선택한다
지니 계수(Gini Index)
지니 계수는 데이터셋 에 포함된 클래스들이 얼머나 섞여 있는지(불순도)를 측정한다
지니 계수의 정의
지니 계수
데이터셋 가 개의 클래스로 구성될 때, 지니 계수 는 다음과 같이 정의된다
- 여기서 는 데이터셋 에서 클래스 가 차지하는 상대적 확률(비중)이다
분할 후의 지니 계수 속성 를 기준으로 데이터셋 를 두 개의 부분 집합 로 이진 분할(Binary partition)했을 때의 지니 계수(불순도)는 다음과 같다
불순도 감소와 속성 선택
나무의 가지를 어디서 칠지 결정하는 논리이다
불순도 감소량 (): 원래의 불순도에서 분할 후의 불순도를 뺀 값이다
선택 기준: 불순도 감소량이 가장 큰 속성(즉, 분할 후의 지니 계수 가 가장 작은 속성)을 테스트 속성으로 선택이다
이진 분할의 특징: 모든 가능한 분할 지점을 열거하여 최적의 지점을 찾는다
예시
14명의 고객 데이터를 바탕으로 수입(income) 속성의 지니 계수를 구해보자
Step 1: 초기 데이터셋의 지니 계수 전체 14명 중 구매(yes) 9명, 미구매(no) 5명인 경우:
Step 2: ‘수입’ 속성으로 분할 시 ‘수입’을 (10명)과 (4명)로 나누었다고 가정해 보자
- 계산 결과:
Step 3: 비교 및 결정 만약 수입을 다르게 묶어서(예: ) 계산한 지니 계수가 0.30이 나왔다면, 0.450보다 더 낮으므로 0.30이 나오는 분할 방식이 더 좋은 방식이 된다
속성 선택 척도 비교(Comparing Attribute Selection Measures)
세 가지 지표는 일반적으로 모두 좋은 결과를 내지만, 각각 특유의 ‘편향(Bias)‘을 가지고 있다
정보 이득 (Information gain): 속성 값이 아주 많은(multivalued) 속성을 선호하는 경향이 있다
정보 이득비 (Gain ratio): 한쪽 파티션이 다른 쪽보다 훨씬 작은 불균형한 분할(unbalanced splits)을 선호하는 경향이 있다
지니 계수 (Gini index):
- 클래스의 개수가 많을 때 계산에 어려움이 있다
- 두 파티션의 크기가 비슷하고, 양쪽 모두 순도(purity)가 높은 분할을 선호한다
과적합(Overfitting)
트리가 훈련 데이터에 너무 집착해서 생기는 문제이다
과적합
유도된 트리가 훈련 데이터에 너무 과하게 맞춰져서 실제 예측력이 떨어지는 현상이다
극단적인 사례: 모든 데이터 행(tuple)마다 개별적인 가지가 있는 경우이다
문제점:
- 가지가 너무 많아지면 데이터 내의 노이즈(noise)나 이상치(outliers)까지 규칙으로 학습해 버린다
- 새로운 데이터에 대한 예측 정확도가 매우 낮아진다
과적합 방지: 트리 가지치기(Tree Pruning)
가지치기는 트리의 복잡도를 줄여 일반화 성능을 높이는 기술이다
사전 가지치기 (Prepruning): 트리를 만드는 도중에 일찍 멈추는 방식이다
- 분할 후의 척도(goodness measure)가 특정 임계값(threshold)보다 낮으면 더 이상 나누지 않는다
- 단점: 적절한 임계값을 정하기가 매우 어렵다
사후 가지치기 (Postpruning): 일단 나무를 끝까지 다 키운(fully grown) 뒤에 가지를 제거하는 방식이다
- 가지를 하나씩 쳐내면서 여러 버전의 트리 시퀀스를 얻는다
- 훈련 데이터가 아닌 별도의 검증 데이터(validation set)를 사용해 가장 성능이 좋은 ‘최적의 가지치기 트리’를 결정한다
대규모 데이터베이스에서의 분류
왜 데이터 마이닝에서 의사결정나무가 여전히 강력한 도구일까?
확장성(Scalability): 수백만 개의 샘플과 수백 개의 속성이 있는 대규모 데이터셋도 합리적인 속도로 처리할 수 있다
장점:
- 다른 분류 방법에 비해 학습 속도가 상대적으로 빠르다
- 분류 규칙을 사람이 이해하기 쉬운 단순한 규칙으로 변환할 수 있다
- 데이터베이스 접근을 위해 SQL 쿼리를 그대로 사용할 수 있다
- 다른 정교한 방법들과 비교해도 정확도가 뒤처지지 않다