MaxMiner: 최대 패턴 마이닝
MaxMiner는 모든 빈번 패턴을 찾는 대신, 더 이상 확장할 수 없는 가장 긴 패턴인 최대 패턴(Max-pattern)을 찾는 데 집중하여 성능을 극대화한 알고리즘이다
MaxMiner의 작동 과정 MaxMiner는 두 번의 스캔을 통해 후보군을 효율적으로 걸러낸다
- 1차 스캔 (1st scan): 빈번 항목들을 찾고, 이를 빈도수가 낮은 순서에서 높은 순서인 오름차순(ascending order)으로 정렬한다
- 예: A, B, C, D, E 순으로 정렬 (E가 가장 빈번함)
- 2차 스캔 (2nd scan): 2-항목집합의 지지도를 확인하면서 동시에 잠재적인 최대 패턴(Potential max-patterns)을 미리 살펴본다
- 예를 들어, AB를 확인할 때 이와 관련된 가장 긴 형태인 ABCDE의 지지도를 함께 체크한다
- BC를 볼 때는 BCDE를, CD를 볼 때는 CDE를 잠재적 최대 패턴으로 둔다
후보군 감소 전략 MaxMiner가 나중에 수행될 수많은 연산을 줄이는 방법은 다음과 같다
- 상향식 가지치기 (Look-ahead): 만약 BCDE가 이미 최대 패턴(빈번함)으로 확인되었다면, 그 부분 집합인 BCD, BDE, CDE 등은 다음 단계에서 굳이 빈번한지 테스트할 필요가 없다
- 하향식 폐쇄성 (Downward Closure): 만약 AC가 빈번하지 않다면(infrequent), 이를 포함하는 더 큰 패턴인 ABC 등은 이후 스캔에서 아예 고려 대상에서 제외한다
폐쇄 패턴 마이닝:CLOSET
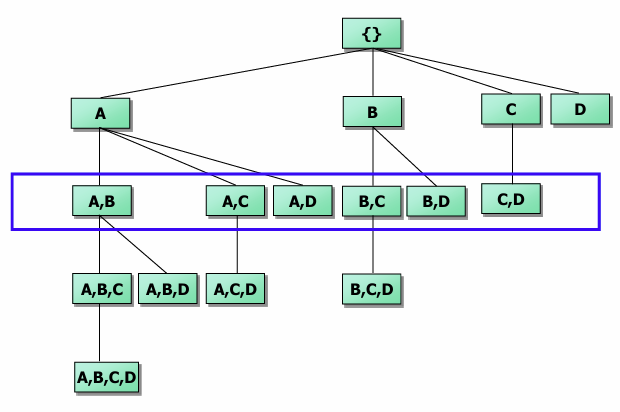
CLOSET의 작동 방식 및 탐색 공간 분할 CLOSET은 FP-tree 구조를 사용하여 효율적으로 빈번 패턴을 탐색한다
- F-list 활용: 모든 빈번 항목을 지지도 내림차순으로 정렬한다
- 에시 F-list: c-e-f-a-d
- 탐색 공간 분할: F-list의 역순으로 탐색을 진행하며 문제를 쪼갠다
- 를 포함하는 패턴들
- 를 포함하지만 는 없는 패턴들
- 를 포함하지만 는 없는 패턴들
- 를 포함하지만 는 없는 패턴들
- 를 포함하지만 는 없는 패턴들
CLOSET의 효율성과 핵심 전략 전통적인 방식과 비교했을 때 CLOSET이 왜 유리한지 보여준다
- 단순한 접근법(Naive approach)의 한계:
- 일단 모든 빈번 항목집합을 다 찾는다
- 그 후 상위 집합과 지지도가 같은 것들을 하나하나 지워나간다
- 문제점: 이 과정은 매우 비용이 많이 든다
- CLOSET의 혁신: 마이닝 과정 중에 FP-tree를 사용하여 재귀적으로 폐쇄 항목집합만 효율적으로 찾아낸다
- 핵심 아이디어: 만약 를 포함하는 모든 트랜잭션이 도 공통적으로 가지고 있다면, 를 굳이 따로 볼 필요 없이 가 빈번 폐쇄 패턴임을 즉시 알 수 있다
CHARM: 수직 데이터 형식을 활용한 마이닝
수직 데이터 형식
수직 데이터 형식
전통적인 방식(수평 형식)이 “어느 거래(TID)에 어떤 물건들이 들어있는가?”를 기록한다면, 수직 형식은 “이 물건(Itemset)은 어느 거래들에 들어있는가?”를 기록한다
- 형식:
- tid-list: 특정 항목집합을 포함하고 있는 트랜잭션 ID들의 리스트이다
알고리즘 작동 단계
- 형식 변환: 데이터셋을 단 한 번 스캔하여 수평 데이터를 수직 형식으로 변환한다(일반적으로 항목의 수가 거래 수보다 훨씬 적기 때문에 변환이 용이하다)
- 후보 생성 및 검증(부터 시작): 빈번 -항목집합들을 조합하여 -항목집합 후보를 만든다
- TID-셋 교집합 (Intersection): 두 항목집합의 TID 리스트를 서로 교집합하면, 그 조합이 함께 나타나는 거래 리스트와 지지도를 즉시 알 수 있다
- 반복: 더 이상 빈번 항목집합이 발견되지 않을 때까지 를 늘리며 반복한다
CHARM의 장단점
- 장점: DB 재스캔 불필요
- 항목집합의 지지도를 구하기 위해 원본 데이터베이스를 다시 뒤질 필요가 없다
- 각 -항목집합의 TID 셋이 이미 지지도 정보를 완벽하게 담고 있기 때문이다
- 단점: 메모리 공간 부담
- 데이터가 매우 많을 경우 TID 리스트 자체가 엄청나게 길어질 수 있다
- 수많은 교집합 연산을 수행하기 위해 큰 메모리 공간이 요구된다
다양한 종류의 연관 규칙 마이닝
단순한 항목 간의 관계를 넘어 데이터의 특성에 따라 다음과 같은 고급 마이닝 기법들이 존재한다
- 다층 연관 규칙 마이닝 (Mining multilevel association)
- 다차원 연관 규칙 마이닝 (Mining multidimensional association)
- 양적 연관 규칙 마이닝 (Mining quantitative association)
- 흥미로운 상관 패턴 마이닝 (Mining interesting correlation patterns)
다층 연관 규칙 마이닝 (Mining multilevel association)
데이터는 계층 구조를 이루는 걍우가 많다
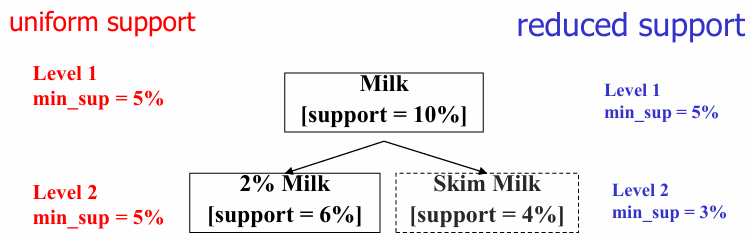
유연한 지지도 설정 계층의 아래로 내려갈수록 개별 항목의 등장 횟수는 줄어들기 때문에, 계층별로 최소 지지도를 다르게 설정하는 것이 중요하다
- 균일 지지도 (Uniform Support): 모든 계층에 동일한 를 적용한다
- 문제점: 상위 계층에 맞추면 하위 계층의 의미 있는 패턴이 무시될 수 있다
- 지지도 감소 (Reduced Support): 하위 계층으로 갈수록 를 낮게 설정한다
- 장점: 세부 항목에서도 유의미한 규칙을 찾아낼 수 있다
중복 필터링 계층 구조를 사용하면 상위 개념과 하위 개념의 규칙이 중복되어 나타날 수 있다. 이를 효율적으로 걸러내야 한다
조상과 자손 관계
- 규칙 1: 우유 통밀빵 [지지도 8%, 신뢰도 70%]
- 규칙 2: 2% 우유 통밀빵 [지지도 2%, 신뢰도 72%]
- 여기서 규칙 1은 규칙 2의 조상 규칙이 된다
중복 판정 기준 하위 규칙(자손)이 다음과 같은 경우 중복(Redundant)으로 간주하고 제거한다
- 지지도의 유사성: 하위 규칙의 지지도가 조상 규칙을 통해 기대되는 수치와 비슷할 때
- 신뢰도의 유사성: 하위 규칙의 신뢰도가 조상 규칙의 신뢰도와 큰 차이가 없을 때
다차원 연관 규칙 마이닝 (Mining Multi-Dimensional Association)
단일 차원 규칙 vs 다차원 규칙
데이터를 분석할 때 고려하는 ‘차원(술어, predicate)‘의 개수에 따라 분류된다
단일 차원 규칙 (Single-dimensional rules): 하나의 차원 또는 술어만을 가진다
- 예:
buys(X, "milk")buys(X, "bread")(표기: milk bread)
다차원 규칙 (Multi-dimensional rules): 개 이상의 차원 또는 술어를 포함한다**
- 차원 간 연관 규칙 (Inter-dimension assoc. rules): 술어가 중복되지 않는 경우입니다.
- 예:
age(X, "19-25")occupation(X, "student")buys(X, "coke")
- 예:
- 혼합 차원 연관 규칙 (Hybrid-dimension assoc. rules): 동일한 술어가 반복되어 나타나는 경우입니다.
- 예:
age(X, "19-25")buys(X, "popcorn")buys(X, "coke")
- 예:
속성 유형(Attribute Types)
다차원 마이닝에 사용되는 데이터 속성은 성격에 따라 다음과 같이 구분된다
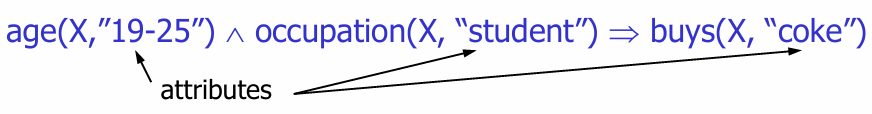
범주형 속성(Categorical Attributes)
- 가능한 값의 수가 유한하다
- 값들 사이에 정해진 순서가 없다 (예: 직업, 색상, 성별 등)
수치형/양적 속성 (Quantitative Attributes)
- 숫자 형태의 데이터이며, 값들 사이에 암시적인 순서가 존재한다 (예: 나이, 가격, 수량 등)
- 특징: 이산화(Discretization) 및 군집화(Clustering) 접근법이 반드시 필요하다
양적 연관 규칙 마이닝 (Mining Quantitative Associations)
치형 속성(나이, 급여 등)을 처리하는 방식에 따라 크게 세 가지 기법으로 나뉜다
정적 이산화(Static Discretization): 미리 정의된 개념 계층을 기반으로 나눈다. 주로 데이터 큐브에서 사용된다
동적 이산화 (Dynamic Discretization): 데이터의 실제 분포에 기초하여 동적으로 구간을 설정한다
군집화 (Clustering): 데이터 간의 거리를 따지는 거리 기반 연관 분석이다
양적 속성의 정적 이산화
마이닝을 시작하기 전에 수치 데이터를 미리 구간으로 나누어 놓는 방식
핵심 원리: 숫자를 범주형 값처럼 취급할 수 있도록 특정 범위(Range)로 대체한다
- 예:
age(X, "19-25")occupation(X, "student")buys(X, "coke")
연산 비용: 관계형 데이터베이스에서 빈번 -술어 집합(k-predicate sets)을 찾기 위해서는 번 또는 번의 테이블 스캔이 필요하다
양적 연관 규칙의 동적 처리 (Quantitative Association Rules)
데이터의 분포를 보고 똑똑하게 구간을 나누는 방식이다
주요 특징
- 수치형 속성을 동적으로(Dynamically) 이산화한다
- 2차원 양적 연관 규칙: 형태로, 두 개의 수치 속성이 하나의 범주형 결과로 이어지는 구조를 분석한다
- 당연히 지지도와 신뢰도가 임계값보다 높아야 한다
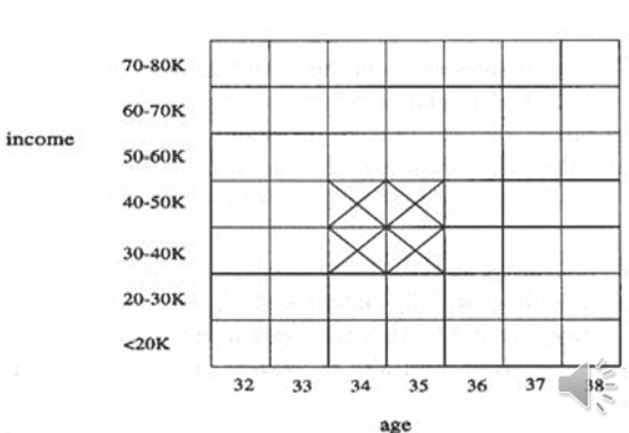
2차원 그리드와 군집화 인접한 연관 규칙들을 2D 그리드 상에서 묶어(Cluster) 더 일반적인 규칙을 형성한다
- 예시:
age(X, "34-35")income(X, "30-50K")buys(X, "high resolution TV")
연관 마이닝에서 상관관계 분석: 흥미도 측정, 상관관계(향상도, Lift)
단순히 지지도와 신뢰도가 높다고 해서 그 규칙이 반드시 의미 있는 것은 아니다
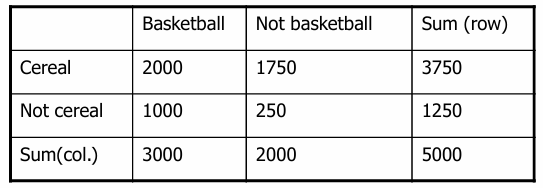
신뢰도(Confidence)의 함정: 농구와 시리얼 예시
- 규칙:
농구를 한다시리얼을 먹는다(지지도 40%, 신뢰도 66.7%) - 문제점: 이 규칙은 오해의 소지가 있다. 왜냐하면 전체 학생 중 시리얼을 먹는 비율은 **75%**이기 때문이다. 즉, 농구를 하는 학생이 시리얼을 먹을 확률(66.7%)보다 그냥 무작위로 뽑은 학생이 시리얼을 먹을 확률(75%)이 더 높다.
- 의미 있는 규칙: 오히려
농구를 한다시리얼을 먹지 않는다(지지도 20%, 신뢰도 33.3%)는 규칙이 지지도와 신뢰도는 낮아도 더 유의미한 상관관계를 보여준다
향상도(Lift)의 정의 사건들이 서로 독립적인지, 아니면 상관관계(종속성)가 있는지 측정하는 지표이다
여기서 는 항목집합 와 가 동시에 발생하는 사건을 의미한다
분할표(Contingency Table)를 통한 계산
실제 계산 예시:
- :
-
해석: 1보다 작으므로, 농구와 시리얼 구매는 음의 상관관계가 있다. (농구를 하면 시리얼을 덜 먹음)
-
:
- 해석: 1보다 크므로, 농구와 시리얼을 먹지 않는 행위는 양의 상관관계가 있다
제약 조건 기반 마이닝
데이터베이스에 존재하는 모든 패턴을 자율적으로(autonomously) 다 찾는 것은 비현실적이다. 왜냐하면, 발견되는 패턴이 너무 많아서 정작 중요한 것에 집중하기 어렵기 때문이다
데이터 마이닝은 상호작용 과정이다 데이터 마이닝은 시스템이 알아서 하는 작업이 아니라, 사용자와의 상호작용(interactive)이 중요하다.
- 사용자가 마이닝할 대상을 직접 지시한다
- 사용자는 데이터 마이닝 질의 언어(Data mining query language)나 GUI를 사용하여 목적을 전달한다
제약 조건 기반 마이닝의 장점
- 사용자 유연성: 무엇을 추출할지에 대한 제약 조건(constraints)을 직접 설정할 수 있다
- 시스템 최적화: 시스템은 주어진 제약 조건을 분석하여 탐색 범위를 좁힘으로써 효율적인 마이닝을 수행한다
데이터 마이닝의 제약 조건 유형
효율적인 분석을 위해 우리가 걸 수 있는 제약 조건은 크게 4가지이다
- 지식 유형 제약:
- 어떤 분석을 할 것인가?(분류, 연관 분석, 군집화 등)
- 데이터 제약:
- 어떤 데이터를 쓸 것인가?(SQL 스타일의 질의 활용)
- 예: “2021년 12월 시카고 매장에서 함께 팔린 제품 쌍을 찾아줘”
- 어떤 데이터를 쓸 것인가?(SQL 스타일의 질의 활용)
- 차원/계층 제약:
- 어떤 속성에 집중할 것인가?
- : 지역, 가격, 브랜드, 고객 카테고리 등 관련 차원 설정
- 어떤 속성에 집중할 것인가?
- 흥미도 제약:
- 어떤 규칙이 유의미한가? (임계값 설정)
- 예: ,
- 어떤 규칙이 유의미한가? (임계값 설정)
제약 조건 푸싱(Constraint Pushing) 전략을 최적화하기 위한 3가지 주요 속성(
비단조성(Anti-Monotonicity)
가장 강력한 가지치기 도구이다. “작은 집합이 안 되면, 그걸 포함하는 큰 집합은 볼 것도 없다”는 논리이다
비단조성
어떤 항목집합 가 제약 조건을 위반하면, 를 포함하는 모든 초월집합(Superset)도 해당 조건을 위반한다
예시:
- 항목집합 의 이익 범위가 이미 15를 넘었다면, 를 포함하는 모든 조합은 조사할 필요 없이 바로 탈락이다
단조성(Monotonicity)
비단조성과는 반대되는 개념이다. “작은 게 통과하면, 큰 건 당연히 통과”라는 논리이다
단조성
정의: 어떤 항목집합 가 제약 조건을 만족하면, 를 포함하는 모든 초월집합도 해당 조건을 만족한다
예시:
- 의 이익 차이가 이미 15 이상이라면, 항목을 더 추가했을 때 그 차이는 유지되거나 더 벌어질 테니 무조건 합격이다
간결성(Succinctness)
DB를 뒤지기 전부터 답을 알 수 있는 ‘가성비’ 좋은 속성이다
간결성
제약 조건 를 만족하는 항목집합들을 아이템들의 선택만으로 간단히 계산(Simply computed)할 수 있는 성질이다
특징: 트랜잭션 데이터베이스(TDB)를 일일이 스캔하지 않아도, 어떤 항목집합이 조건을 만족하는지 즉시 판별 가능하다
예시:
- 가격이 이하인 아이템이 하나라도 포함된 집합은 다 합격이다. DB를 안 봐도 아이템 목록만 보면 미리 알 수 있다
최적화: 간결한 제약 조건은 빈도를 세기 전(Pre-counting)에 미리 적용하여 검색 공간을 확 줄일 수 있다
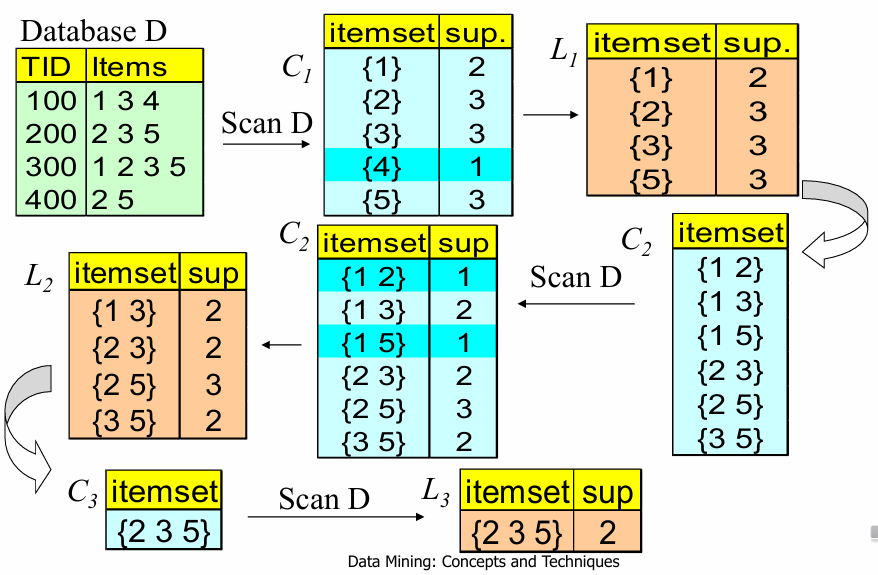
기본 Apriori 알고리즘 (Review)
제약 조건이 없을 때의 표준적인 과정이다
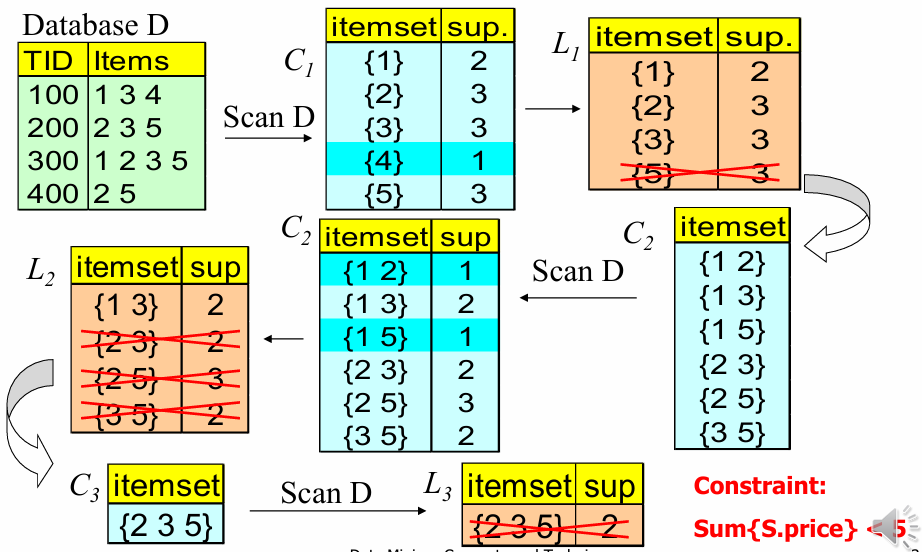
나이브(Naïve) 알고리즘: Apriori + 제약 조건
가장 단순한 방식으로, 마이닝이 어느 정도 진행된 후 제약 조건을 적용한다
최적화 1: 비단조성 제약 조건 푸싱 (Pushing Deep)
비단조성(Anti-monotone) 성질을 이용하여 알고리즘 깊숙이 제약 조건을 주입한다
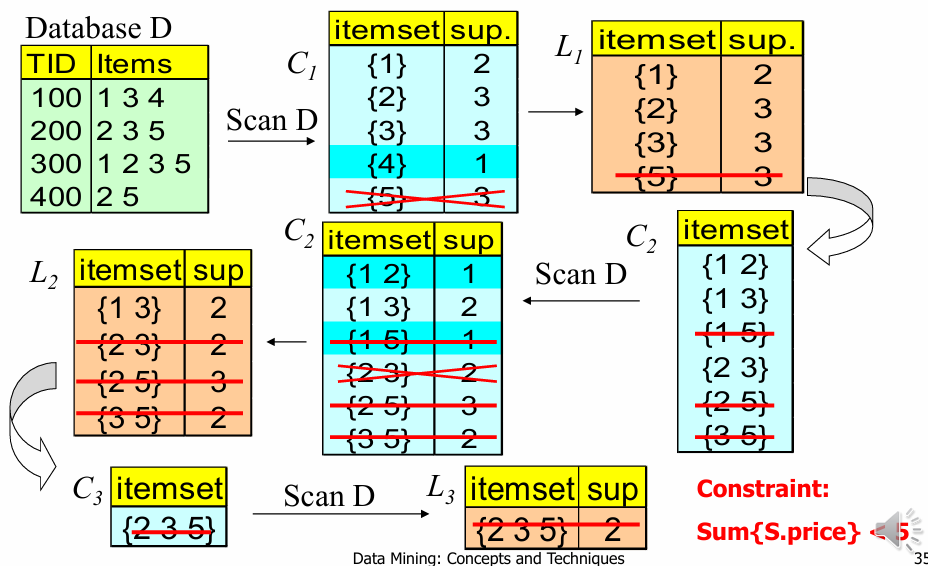
최적화 2: 간결성 제약 조건 푸싱 (Pushing Deep)
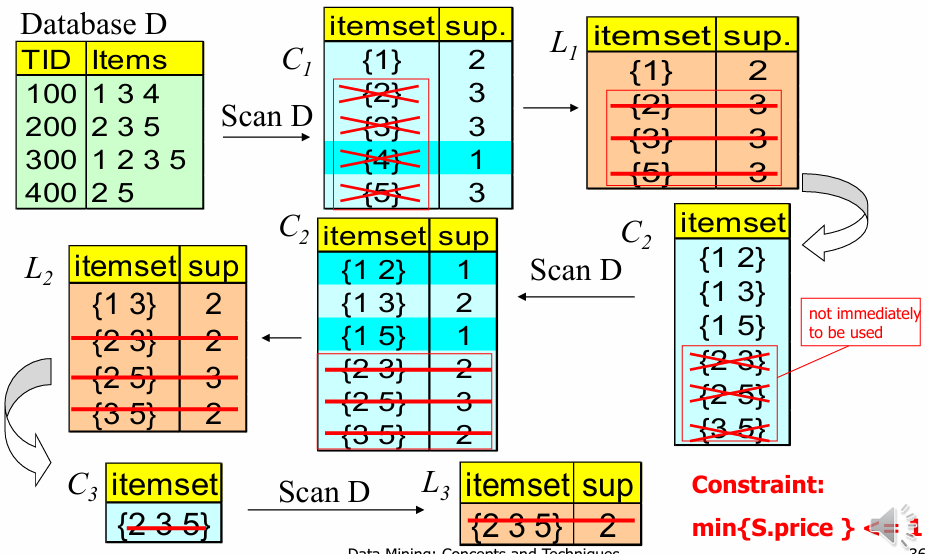
간결성(Succinct) 성질을 이용하여 DB를 보기도 전에 가망 없는 아이템을 쳐낸다
까다로운(Tough) 제약 조건의 변환
일반적으로 평균과 같은 제약 조건은 항목을 추가할 때 값이 커질 수도, 작아질 수도 있기 때문에 비단조성(Anti-monotone)이나 단조성(Monotone) 중 어디에도 속하지 않는 ‘까다로운’ 조건이다
핵심 아이디어: 항목 정렬 (Ordering Items):
- 까다로운 제약 조건을 적절한 항목 정렬을 통해 비단조성 또는 단조성 성질을 갖도록 변환한다
- 이를 통해 효율적인 가지치기(Pruning)가 가능해진다
사례 분석: 이 조건은 단순히 보면 비단조성이 아니지만, 다음과 같은 과정을 거치면 성질이 변한다
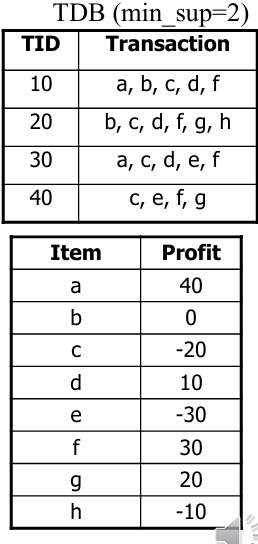
- Step 1: 이익(Profit) 내림차순 정렬: 제공된 표의 Profit 데이터를 큰 순서대로 나열한다
- 데이터: a(40), f(30), g(20), d(10), b(0), h(-10), c(-20), e(-30)
- 정렬 결과:
- Step 2: 비단조성 확인: 이제 정렬된 순서대로 항목을 추가한다고 가정해 본다
- 만약 항목집합 가 조건()을 위반한다면?
- 그다음에 올 항목인 는 현재 포함된 항목들()보다 이익이 무조건 낮거나 같다
- 따라서 의 평균은 절대로 이전보다 높아질 수 없으며, 당연히 조건을 계속 위반하게 된다 결론: 적절한 정렬을 통해 조건이 비단조성(Anti-monotone) 성질을 갖게 되었다