데이터 마이닝(Data Mining)
데이터 마이닝
대규모로 축적된 데이터 안에서 통계적 규칙, 패턴, 지식 등 유용한 정보를 찾아내어 의사결정에 활용하는 기술과 과정이다
분야나 관점에 따라 다음과 같은 다양한 용어로 불린다
- KDD: 데이터베이스 내 지식 발견 (Knowledge Discovery in Databases)
- 지식 추출 (Knowledge Extraction)
- 데이터/패턴 분석 (Data/Pattern Analysis)
- 데이터 고고학 (Data Archeology) / 데이터 드레징 (Data Dredging)
- 정보 수확 (Information Harvesting)
- 비즈니스 인텔리전스 (Business Intelligence, BI) 등
단순히 데이터를 다룬다고 해서 모두 데이터 마이닝이라고 하지는 않는다. 다음 경우들은 데이터 마이닝의 범주에서 제외된다
- 단순 검색 및 쿼리 처리 (Simple search and query processing): 특정 조건의 데이터를 찾아내는 단순 조회 작업
- 연역적 전문가 시스템 (Deductive expert systems): 이미 알려진 규칙을 바탕으로 결과를 도출하는 시스템
데이터 마이닝은 하나의 기술이 아니라, 다양한 학문 분야가 모여 이루어진 결정체이다
KDD 프로세스(Knowledge Discovery in Databases)
KDD 프로세스
대규모 데이터셋에서 통계적 패턴이나 의미 있는 지식을 도출하는 구조화된 데이터 마이닝 절차
데이터 마이닝은 지식 발견 과정의 핵심 단계이다. 원시 데이터가 지식이 되기까지의 전체 흐름은 다음과 같다
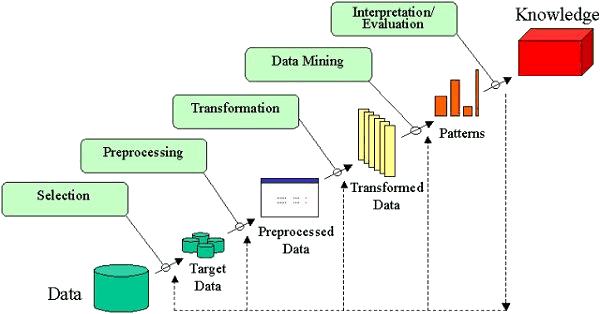
데이터 마이닝과 비즈니스 인텔리전스(BI)
비즈니스 인텔리전스
기업이 방대한 원시 데이터를 수집, 저장, 분석하여 의사 결정에 필요한 유의미한 인사이트를 도출하는 기술과 프로세스
상위 단계로 올라갈수록 의사결정을 지원하는 잠재력이 커진다. 각 층별 역할과 담당자는 다음과 같다
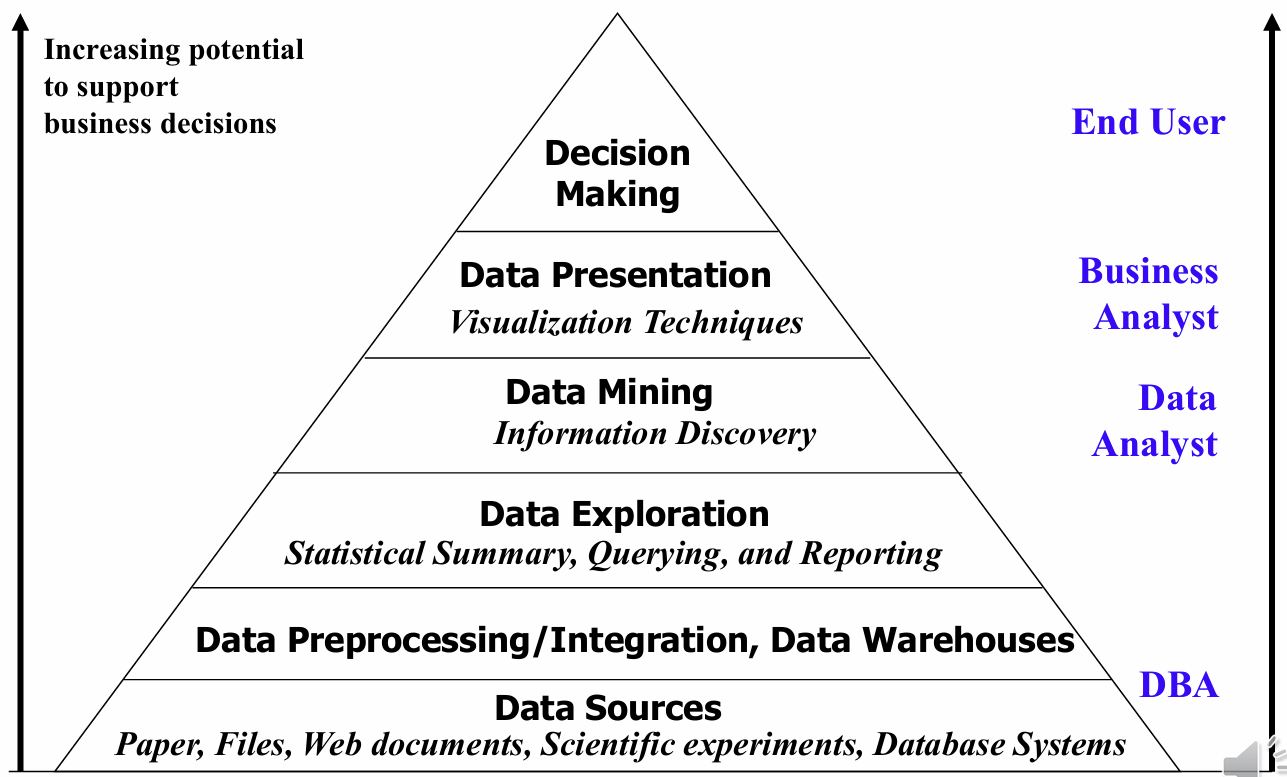
왜 전통적인 데이터 분석으로는 부족한가?
기존의 분석 방식은 오늘날의 데이터를 감당하기 어려운 이유 4가지는 다음과 같다
엄청난 데이터 양: 페타바이트(PB) 단위의 데이터를 처리하기 위해 알고리즘의 확장성(Scalability)이 필수적이다
데이터의 고차원성: 마이크로어레이(Micro-array)와 같은 데이터는 수만 개의 차원(변수)을 가진다
데이터의 복잡성:
- 데이터 스트림, 센서 데이터
- 시계열 데이터, 시공간 및 순서 데이터
- 구조화된 데이터, 그래프, 소셜 네트워크, 다중 연결 데이터
- 이기종 DB 및 레거시(과거) DB
- 공간, 멀티미디어, 텍스트 및 웹 데이터
- 소프트웨어 프로그램, 과학적 시뮬레이션 결과물
새롭고 정교한 애플리케이션의 등장: 더 복잡하고 고도화된 분석 결과가 필요한 환경이 조성되있다
데이터 마이닝의 분류 체계
데이터 마이닝은 크게 두 가지 목적과 네 가지 관점으로 분류할 수 있다
일반적인 분류
- 기술적 데이터 마이닝 (Descriptive data mining): 데이터가 가진 일반적인 특성을 요약하고 묘사하는 방식이다
- 예측적 데이터 마이닝 (Predictive data mining): 현재 데이터를 바탕으로 추론을 수행하여 미래의 경향을 예측하는 방식이다
관점에 따른 네 가지 분류
- 데이터 관점 (Data view): 어떤 종류의 데이터를 마이닝할 것인가?
- 지식 관점 (Knowledge view): 어떤 종류의 지식을 발견할 것인가?
- 기법 관점 (Method view): 어떤 분석 기술을 활용할 것인가?
- 응용 관점 (Application view): 어떤 분야에 적용할 것인가?
데이터 마이닝의 다차원적 관점
데이터 마이닝을 다각도에서 분석할 때 고려해야 할 구체적인 요소들이다
| 분석 대상 데이터 | 주요 내용 및 예시 |
|---|---|
| 분석 대상 데이터(Data to be mined) | 관계형 DB, 데이터 웨어하우스, 트랜잭션 데이터, 스트림 데이터, 객체지향/관계형 DB, 능동(Active) DB, 공간 데이터, 시계열 데이터, 텍스트, 멀티미디어, 이기종(Heterogeneous) 데이터, 레거시 데이터, WWW(웹) 등 |
| 추출할 지식(Knowledge to be mined) | 특징화(Characterization), 차별화(Discrimination), 연관 분석(Association), 분류(Classification), 클러스터링(Clustering), 추세/편차 분석, 이상치(Outlier) 분석 등 (다중 기능 및 다단계 마이닝 포함) |
| 활용 기법(Techniques utilized) | 데이터베이스 지향 기법, 데이터 웨어하우스(OLAP), 기계 학습(Machine learning), 통계학, 시각화 등 |
| 적용 분야(Applications adapted) | 소매업(Retail), 통신, 금융, 부정 행위 분석(Fraud analysis), 바이오 데이터 마이닝, 주식 시장 분석, 텍스트 마이닝, 웹 마이닝 등 |
마이닝을 위한 데이터
데이터 마이닝의 대상이 되는 데이터셋은 크게 전통적인 방식과 심화된 방식으로 나뉜다
데이터베이스 지향 데이터셋 및 응용 가장 기조척이고 구조화된 형태의 데이터이다
- 관계형 데이터베이스 (Relational database): 표(Table) 형태로 정리된 데이터
- 데이터 웨어하우스 (Data warehouse): 여러 소스에서 수집된 방대한 데이터의 통합 저장소
- 트랜잭션 데이터베이스 (Transactional database): 구매 이력 등 거래 기록 중심의 데이터
심화 데이터셋 및 응용 현대 데이터 사이언스에서 다루는 복잡하고 비구조화된 데이터들이다
- 데이터 스트림 및 센서 데이터: 실시간으로 흘러들어오는 데이터
- 시계열 및 시퀀스 데이터: 시간 순서에 따른 데이터 (예: 생물학적 서열)
- 구조 데이터 및 그래프: 소셜 네트워크, 다중 연결 데이터 등
- 객체-관계형 데이터베이스: 객체 지향 개념이 도입된 DB
- 이기종 및 레거시 데이터베이스: 서로 다른 형태나 오래된 시스템의 데이터
- 공간 및 시공간 데이터: 위치 정보가 포함된 데이터
- 멀티미디어, 텍스트, WWW(웹): 이미지, 비디오, 문서 및 웹 페이지 데이터
데이터 마이닝의 기능(지식)
데이터 마이닝을 통해 구체적으로 ‘무엇을 할 수 있는지’에 대한 설명이다
다차원 개념 묘사
- 특성화(Characterization): 데이터의 특성을 일반화하고 요약함
- 차별화(Discrimination): 서로 다른 데이터 그룹을 비교하고 대조함 (예: 건조한 지역 vs 습한 지역)
빈번한 패턴 맟 연관 분석
- 데이터 내에서 자주 발생하는 상관관계를 찾음
- 예시: 기저귀를 사는 사람이 맥주도 같이 살 확률이 높다는 분석 ()
분류 및 예측
- 미래를 예측하기 위해 클래스를 구분하는 모델(함수)을 구축함
- 예시: 기후를 바탕으로 국가를 분류하거나, 연비를 바탕으로 자동차를 분류
- 알려지지 않았거나 누락된 수치형 값을 예측함
군집 분석
- 클래스 라벨을 모를 때 사용함. 데이터를 묶어서 새로운 클래스를 형성 (예: 주택을 그룹화하여 분포 패턴 파악)
- 원칙: 클래스 내 유사도는 최대화하고, 클래스 간 유사도는 최소화함
이상치 분석
- 데이터의 일반적인 행동 양식을 따르지 않는 ‘튀는’ 데이터를 분석함
- 단순 노이즈일 수도 있지만, 부정 결제 감지(Fraud detection)나 희귀 사건 분석에 매우 유용함
추세 및 진화 분석
- 추세 및 편차: 회귀 분석 등을 통해 데이터의 흐름을 파악
- 순차적 패턴 마이닝: ‘디지털 카메라 구매 후 대용량 SD 메모리 구매’ 같은 순서를 파악
- 주기성 분석 및 유사도 기반 분석 포함
18가지 데이터 마이닝 후보 알고리즘
이 리스트는 ICDM(국제 데이터 마이닝 컨퍼런스)에서 선정된 가장 영향력 있는 알고리즘들이다
분류 (Classification)
- #1. C4.5: 의사결정 나무(Decision Tree)의 대표 주자로, 데이터를 분류하는 규칙을 생성한다
- #2. CART: 분류 및 회귀 나무로, 이진 분할을 사용하는 알고리즘이다
- #3. kNN (k-Nearest Neighbours): 새로운 데이터를 가장 가까운 개의 이웃 데이터와 비교하여 분류한다
- #4. Naive Bayes: 베이즈 정리를 이용한 확률적 분류 기법이다
통계적 학습 및 연관 분석 (Statistical Learning & Association)
- #5. SVM (Support Vector Machine): 데이터를 분류하는 최적의 경계(Hyperplane)를 찾는 강력한 모델이다
- #6. EM (Expectation-Maximization): 데이터의 확률 모델을 추정하는 반복 알고리즘이다
- #7. Apriori: 데이터 간의 연관 규칙(예: 장바구니 분석)을 찾는 고전적 알고리즘이다
- #8. FP-Tree: 후보 생성 없이 빈번한 패턴을 마이닝하는 효율적인 기법이다
링크 및 그래프 마이닝 (Link & Graph Mining)
- #9. PageRank: 구글의 검색 엔진 기초가 된 알고리즘으로, 웹 페이지의 중요도를 측정한ㄷ
- #10. HITS: 허브(Hub)와 권위(Authority) 개념을 이용해 웹 페이지 구조를 분석한다
- #18. gSpan: 그래프 구조 내에서 빈번한 부분 구조(Substructure)를 찾는 기법이다
군집화 (Clustering)
- #11. K-Means: 데이터를 개의 군집으로 묶는 가장 대표적인 비지도 학습 알고리즘이다
- #12. BIRCH: 대규모 데이터셋에 적합한 계층적 군집화 방법이다
앙상블 및 기타 (Ensemble & Others)
- #13. AdaBoost: 약한 분류기들을 결합하여 강한 분류기를 만드는 부스팅 기법이다
- #14 & #15. GSP & PrefixSpan: 데이터의 순차적 패턴(Sequential Patterns)을 찾는 알고리즘이다
- #16. CBA: 분류와 연관 규칙 마이닝을 결합한 통합 기법이다
- #17. Rough Sets: 불확실하거나 불완전한 데이터로부터 지식을 도출하는 러프 집합론 기반 기법이다
ICDM’06 최종 선정 Top-10 알고리즘
전 세계 전문가들의 투표를 통해 최종적으로 가장 중요하다고 평가받은 10가지 알고리즘 순위이다
| 순위 | 알고리즘 명칭 | 주요 특징 |
|---|---|---|
| #1 | C4.5 | 의사결정 나무 (분류 분야의 최고 권위) |
| #2 | K-Means | 가장 널리 쓰이는 군집화(Clustering) 기법 |
| #3 | SVM | 높은 정확도를 자랑하는 통계적 분류 모델 |
| #4 | Apriori | 연관 규칙 마이닝의 표준 |
| #5 | EM | 확률 기반의 군집화 및 파라미터 추정 |
| #6 | PageRank | 링크 분석 및 검색 랭킹의 핵심 |
| #7 | AdaBoost | 예측 성능을 극대화하는 앙상블 기법 |
| #7 | kNN | 직관적이고 구현이 쉬운 분류 기법 |
| #7 | Naive Bayes | 빠르고 효율적인 확률 모델 |
| #10 | CART | 분류 및 회귀 모두 가능한 의사결정 나무 |