1. 정규 문법 (Regular Grammars, RG)
정규 문법 (Regular Grammar)
정규 문법은 정규 언어를 생성하는 생성 규칙(Production Rule)의 집합이다. 변수 전개가 일어나는 방향에 따라 크게 두 가지 형태로 나뉜다
정규 문법의 두 가지 종류
- 우선형 문법 (Right-linear Grammar):
- 모든 생성 규칙이 또는 형태이다
- (단, 이며 단말 기호의 문자열을 의미, 는 변수)
- 변수가 항상 문자열의 오른쪽 끝에만 나타난다
- 좌선형 문법 (Left-linear Grammar):
- 모든 생성 규칙이 또는 형태이다
- 변수가 항상 문자열의 왼쪽 끝에만 나타난다
1.1 정규 표현식 유도 예시
문법이 주어졌을 때, 반복적인 변수 대입을 통해 해당 문법이 생성하는 언어를 정규 표현식(RE)으로 표현할 수 있다
- 우선형 예시:
- 유도 과정:
- 좌선형 예시:
- 유도 과정:
- (참고: 유도 방향이 왼쪽에서 오른쪽으로 뻗어나갑니다.)
1.2 문법과 오토마타의 상호 변환
오토마타의 상태(State)는 문법의 변수(Non-terminal)와 1:1로 대응된다
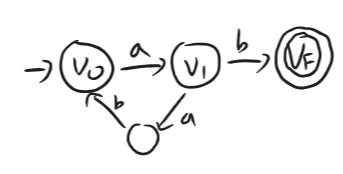
우선형 문법 DFA 변환 문법의 생성 규칙을 오토마타의 상태 전이 화살표로 바로 바꿀 수 있다
- 규칙: 는 상태 에서 입력 를 받아 상태 로 가는 전이()가 된다
- 예시:
- (생성되는 RE: )
DFA 우선형 문법 변환 DFA의 그래프 구조를 그대로 생성 규칙으로 옮겨 적는다
- 예시 언어:
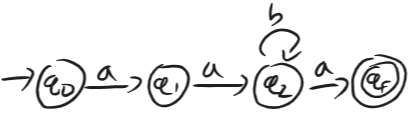
- 각 상태 를 문법 변수()로 설정하고 전이에 따라 규칙을 생성한
- (수락 상태는 전이로 종료)
좌선형 문법 변환
우선형 문법은 “상태 입력 다음 상태” 순서로 직관적인 변환이 가능하지만, 좌선형은 최종 상태에서 거꾸로 거슬러 올라가는 역방향 구조이다. 따라서 직접 변환하기보다는, 오토마타를 뒤집은(Reverse) 뒤 우선형으로 구하고 다시 뒤집는 동치 성질을 이용해 변환하는 것이 일반적이다
2. 정규 언어의 폐쇄 성질 (Closure Properties)
정규 언어 가 있을 때, 특정 연산을 거쳐 만들어진 새로운 언어 역시 여전히 정규 언어의 범주에 속한다는 수학적 성질이다
| 연산 종류 | 기호 | 설명 및 증명 아이디어 |
|---|---|---|
| 합집합 | 정규 표현식 로 쉽게 표현 가능 | |
| 결합 | 정규 표현식 로 표현 가능 | |
| 여집합 | DFA의 수락 상태()와 비수락 상태()를 반전시켜 구성 | |
| 교집합 | 1. 드 모르간의 법칙() 적용 2. Product Construction ( 상태 교차 곱) 증명 | |
| 차집합 | 와 동일하므로 정규 언어 연산의 조합임 | |
| 역순 | 오토마타의 방향을 뒤집고 시작/수락 상태를 교체하면 됨 |
2.1 동형 사상 (Homomorphism, )
동형 사상
언어에 속한 각각의 단일 알파벳을 특정 문자열로 통째로 치환하는 함수 에 대해, 정규 언어 의 치환 결과 집합인 역시 정규 언어이다
- 예시 1 (집합 치환):
- 설정:
- 치환 함수:
- 대상 언어:
- 결과:
- 예시 2 (정규 표현식 치환):
- 설정: 치환 함수
- 정규 표현식:
- 결과:
2.2 우측 몫 (Right-Quotient, )
우측 몫
두 언어 에 대해, 에 속하는 문자열 중 뒷부분(접미사)이 의 패턴과 일치하는 경우, 그 뒷부분을 잘라내고 남은 앞부분들의 집합이다
- 수식 예시:
- 결과: (즉, RE로는 )
- DFA 기반 증명 아이디어: 을 인식하는 DFA에서, 특정 상태 에서 출발해 에 속하는 문자열을 읽고 기존 수락 상태에 도달할 수 있다면, 그 상태 를 새로운 수락 상태로 바꾼. 이렇게 변형된 DFA가 인식하는 언어가 바로 가 된다
2.3 교집합 연산과 Product Construction 증명
정규 언어의 교집합()이 정규 언어임을 증명하기 위해 두 DFA를 병렬로 결합한 Product DFA를 구성한다
- 예시 언어:
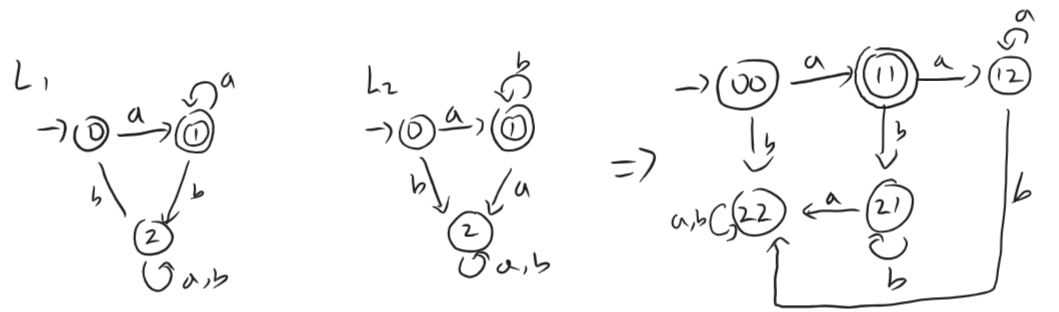
- 증명 방법:
- 의 상태 와 의 상태 를 묶어 새로운 상태 쌍 를 만든다
- 새로운 오토마타의 수락 상태는 두 DFA가 동시에 수락 상태인 경우에만 해당한다
- 결과적으로 교집합 만을 인식하는 새로운 DFA가 완성되므로, 교집합 역시 정규 언어임이 증명한다
3. 정규 언어의 주요 판정 문제 (Decision Problems)
특정 언어가 정규 언어의 3대 표준 표현(RE, DFA, RG) 중 하나로 주어졌을 때, 컴퓨터(알고리즘)를 통해 다음 질문들에 대한 명확한 답(Yes/No)을 유한 시간 내에 도출할 수 있다
3.1 소속 문제 (Membership Problem: ?)
질문: 임의의 문자열 가 언어 에 속하는가?
- 판별 알고리즘: 언어 을 인식하는 DFA를 구성한 뒤, 문자열 를 입력하여 시뮬레이션합니다. 문자열을 다 읽고 난 후 최종 상태가 수락 상태이면 Yes, 아니면 No를 반환한다
- 문자열 길이가 일 때 시간에 빠르게 판독 가능하다
3.2 공백 / 유한 / 무한 판정 (Emptiness / Finiteness)
질문: 언어 이 텅 비어있는가? 문자열 개수가 유한한가, 무한한가?
- 공백 판정 (?):
- DFA의 상태 그래프에서 시작 상태로부터 수락 상태로 도달할 수 있는 경로(Path)가 단 하나라도 존재하는지 확인한다(BFS, DFS 탐색 활용)
- 경로가 아예 없다면 언어는 공집합이다
- 무한 판정 (Infinite?):
- 불필요한 상태(시작점에서 도달 불가, 수락점으로 도달 불가)를 다 제거한다
- 남은 유효한 상태 전이 그래프 내에 사이클(Cycle, 루프)이 존재하는지 확인한다
- 유효한 경로 상에 루프가 있다면 무한히 많은 문자열 생성이 가능하므로 무한(Infinite), 루프가 하나도 없다면 유한(Finite)한다
3.3 동등성 문제 (Equivalence Problem: ?)
질문: 서로 다르게 생긴 두 정규 표현식이나 오토마타 가 실제로는 완전히 같은 언어를 나타내는가?
- 판별 알고리즘 1 (대칭 차집합 이용):
- 두 언어의 차집합을 결합하여 다음 식 를 구성한다
- 이 에 대해 위에서 배운 공백 판정(Emptiness Test)을 실행하여 결과가 (비어 있음)으로 나오면, 두 언어는 완전히 동일하다
- 판별 알고리즘 2 (최소화 이용):
- 두 DFA를 각각 최소화(Minimization) 알고리즘을 돌려 가장 작은 형태로 만든다
- 최소화된 두 DFA의 구조(상태 개수와 전이 화살표)가 완전히 일치(Isomorphic)하는지 비교한다