이진 탐색(Binary search)
이진 탐색(Binary search)
이진 탐색은 정렬된 리스트에서 탐색 범위를 매 단계마다 절반씩 좁혀가며 특정 값을 찾아내는 효울적인 탐색 알고리즘이다. 반드시 데이터가 오름차순이나 내림차순으로 정렬되어 있어야만 사용할 수 있다
성공과 실패 조건 이진 탐색은 무한정 반복하는 것이 아니라, 특정 시점에 탐색을 멈춰야 한다. 이때 프로그램의 판단 기준을 정의한다
- 성공 조건: 리스트 안에 찾고자 하는 값이 존재하는 경우
- 실패 조건: 리스트 안에 더 이상 확인할 요소가 없는 경우. 즉, 시작 지점이 끝지점보다 커질 때
탐색 원리와 과정 이진 탐색은 매 단계마다 탐색 범위를 절반으로 줄여나가는 것이 핵심이다
- 중간값 확인: 리스트의 중간 위치를 계산하여 해당 요소와 찾으려는 값(query)을 비교한다
- 세 가지 경우의 수
- 중간값 = 쿼리: 탐색이 성공해 중간 위치를 반환한다
- 중간값 > 쿼리: 찾는 값이 왼쪽에 있으므로, 끝 지점을
middle -1로 옮겨 왼쪽 구간을 탐색한다 - 중간값 < 쿼리: 찾는 값이 오른쪽에 있으므로, 시작 지점을
middle +1로 옮겨 오른쪽 구간을 탐색한다
탐색 로직을 코드 정리하자면 다음과 같다:
// 이진 탐색 함수
int binsearch(int list[], int query, int start, int end) {
int middle;
// 시작 지점이 끝 지점보다 작거나 같을 때까지 반복
while (start <= end) {
middle = (start + end) / 2; // 중간 위치 계산
// 1. 중간값과 쿼리 비교 (비교 결과에 따라 -1, 0, 1 반환 가정)
switch (compare(list[middle], query)) {
case -1: // list[middle] < query 인 경우
start = middle + 1; // 오른쪽 구간 선택
break;
case 0: // list[middle] == query 인 경우
return middle; // 인덱스 반환 (성공)
case 1: // list[middle] > query 인 경우
end = middle - 1; // 왼쪽 구간 선택
break;
}
}
return -1; // 탐색 실패 (값이 없음)
}순환 알고리즘(Recursive Algorithms)
순환 알고리즘 정의
어떤 알고리즘이 자기 자신을 다시 호출하여 문제를 해결하는 방식을 말한다
원래의 문제를 해결하기 위해, 입력 크기가 더 작은 동일한 문제의 인스턴스로 나누어 해결한다. 예를 들면 팩토리얼이 있다
이진 탐색
이진 탐색을 while문 대신 재귀 호출로 구현한 형태이다. 동작 방식은 이진 탐색에서 찾는 동작에서 찾아야되는 구간에 대해 함수를 다시 호출한다. 종료 조건은 값을 찾거나, 시작 지점이 끝 지점보다 커질 때이다
코드로 보면
int binsearch (int list[], int query, int start, int end){
int middle;
if (start <= end){
middle=(start+end) / 2;
switch(compare(list[middle], query)){
case -1 : return binsearch(list, query, middle+1, end);
case 0 : return middle;
case 1 : return binsearch(list, query, start, middle-1);
}
}
return -1;
}
순열 생성(Permutations)
주어진 원소들로 만둘 수 있는 모든 가능한 배열의 순서를 출력하는 문제이다
순열을 만드는 법은 아주 단순한 반복적 구조를 가진다
- ‘a’를 첫 번째 자리에 고정 + 나머지 의 순열을 구함
- ‘b’를 첫 번째 자리에 고정 + 나머지 의 순열을 구함
- ‘c’를 첫 번째 자리에 고정 + 나머지 의 순열을 구함
- ‘d’를 첫 번째 자리에 고정 + 나머지 의 순열을 구함
이 과정에서 의 순열을 구할 때도 다시 “b를 고정하고 의 순열을 구하는” 식으로 재귀가 일어난다
코드로 보면
void perm(char *list, int i, int n) { //I: start, n: total // base index: 1
int j, temp;
if (i==n) {
for(j=0; j<=n; j++)
printf(“%c ”, list[j]);
printf(“\n”);
} else { //a b c
for(j=i; j<=n; j++) {
swap(list[i], list[j]); //b a c
perm(list, i+1, n);
swap(list[i], list[j]); //c b a
}
}
}성능 평가
알고리즘의 성능 분석은 하드웨어 성능에 의존하지 않는 기계 독립적 방식인 복잡도 이론을 기반으로 한다. 복잡도는 두 가지가 있다
- 공간 복잡도: 프로그램이 완료될 때까지 실행되는 데 필요한 메모리 양
- 시간 복잡도: 프로그램이 완료될 때까지 실행되는 데 필요한 컴퓨팅 시간
공간 복잡도
공간 복잡도 정의
프로그램이 사용하는 총 공간 는 크게 고정 공간과 가변 공간의 합으로 정의된다
고정 공간 요구 사항(C) 입력과 출력의 개수나 크기에 의존하지 않는 공간이다. 프로그램의 특성에 따라 일정하게 유지되는 상수(Constant) 값이다
- 예시:
- 명령어 공간(Instruction Space)
- 단순 변수
- 고정 크기의 구조체 변수
- 상수
가변 공간 요구 사항() 해결하려는 문제의 특정 인스턴스 크기에 의존하는 공간이다. 데이터의 크기가 커질수록 필요한 메모리 공간도 함께 늘어난다
- 예시:
- 입력 데이터의 크기에 따라 크기가 변하는 동적 배열이나 구조체 변수
- 재귀 호출 시 쌓이는 스택 공간
총 공간 복잡도 공식
- : 총 공간 요구 사항
- : 고정 공간
- : 인스턴스 의 특성에 따라 변하는 가변 공간 함수
공간 복잡도 계산 예시
단순 산술 함수
- 특징: 입력 데이터의 크기에 상관없이 항상 일정한 공간만 사용한다
float abc(float a, float b, float c){
return a+b+b*c+(a+b+c)/(a+b)+4.00;
}-
분석:
- input: 단순 변수 3개 (float a,b,c)
- output: 단순 값 1개
- 가변 공간 (): 0
-
결론: 오직 고정 공간 요구 사항만 존재한다
반복문을 이용한 합계 함수
- 특징: 리스트를 입력받지만, 배열 자체를 복사하지 않는다
float sun(float list[], int n){
float temp sum = 0;
int i;
for(i=0; i<n; i++)
temp_sum += list[i];
return temp_sum;
}- 분석:
- input: 배열의 주소(포인터), 정수 n
- output: 단순 값 1개
- 가변 공간: (): 0
배열 전달 방식: C언어는 배열을 포인터로 전달한다. 즉, 첫 번째 요소의 주소만 전달하므로 배열이 아무리 커도 함수 내부에서 사용하는 주소 값의 크기는 고정되어 있다
- 결론: 배열의 크기가 커져도 루프 내에서 추가로 사용하는 변수는 고정적이므로 가변 공간이 필요하지 않는다
재귀를 이용한 합계 함수
- 특징: 함수가 자기 자신을 호출할 때마다 시스템 스택에 새로운 데아터 공간이 생성된다. 이 부분이 공간 복잡도에서 가장 주의해야 할 대목이다
float rsum(float list[], int n){
if(n) return rsum(list,n-1)+list[n-1];
return 0;
}메모리 구성(재귀 호출 1회당)
| 타입 | 이름 | 바이트 수 |
|---|---|---|
| 매개변수: 배열 포인터 매개변수: 정수 복귀 주소 | list[] n | 4 4 4 |
| 합계(1회 호출당) | 12 |
- 총 가변 공간 계산:
- 배열에 MAX_SIZE 만큼의 숫자가 있다고 가정하면, 함수는 총 MAX_SIZE번 재귀 호출된다
- 총가변 공간:
시간 복잡도
시간 복잡도 정의
프로그램 가 실행되는 데 걸리는 시간 는 컴파일 시간과 실행 시간의 합이다
- 컴파일 시간: 고정 공간 요구 사항과 유사하게 한 번 정해지면 크게 변하지 않는다
- 실행 시간():
- 하드웨어 성능에 의존하지 않기 위해 프로그램이 수행하는 연산의 횟수를 센다
- 기계 독립적인 추정치를 제공한다
프로그램 단계: 구문론적 또는 의미론적으로 의미 있는 단위로, 실행 시간이 인스턴스의 특성에 독립적인 코드 조각을 말한다
시간 복잡도 계산 예시
반복문을 이용한 합계
float sum (float list[], int n) {
float temp_sum=0; //초기화 문장으로 1회 실행
int i; //변수 선언은 실행 단계로 치지 않는다-> 0
for(i = 0; i < n; i++)//n+1회: i가 0부터 n-1까지 n번 참이 되어 루프를 돌고, 마지막에 i==n이
//되어 거짓임을 확인하는 1회가 추가된다
temp_sum += list[i];//루프 몸체이므로 참일 때만 실행되어 n회 실행된다
return temp_sum; //함수를 마치며 1회 실행된다
} //총합: 1+(n+1)+n+1=2n+3재귀 합계
float rsum(float list[], int n) {
if(n) //n+1회: n이 1일 떄까지 재귀 호출이 일어나 n번 확인하고
//마지막에 n=0이 되어 else로 가기 전 확인하는 1회가 추가
return rsum(list,n-1)+list[n-1];//if(n)이 참일 때 실행된다. n부터 1까지 총 n회 호출된다
return list[0]; //n이 0이 되어 재귀가 끝날 때 딱 1회 실행된다
} //총합: (n+1)+n+1=2n+2행렬 덧셈
void add(int a[][M_SIZE], ...) {
int i, j;
for(i = 0; i < rows; i++) //rows회 + 1회 마지막 거짓
for(j = 0; j < cols; j++) //rows번 마다 각각 cols+1회
c[i][j] = a[i][j] + b[i][j]; //가장 안쪽의 실제 연산은 두 루프가 모두 참일 때만 실행
} //따라서 rows*(cols+1)회
//총합: 2(rows*cols)+2(rows)+1점근적 표기법
Big-O 표기법
Big-O 정의
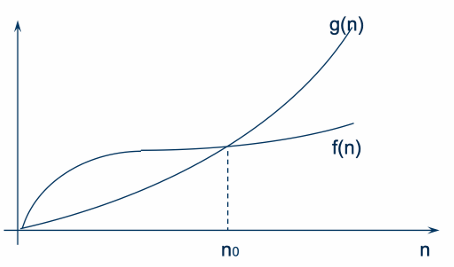
함수 의 성장이 함수 에 의해 제한된다는 것을 수학적으로 표현한 것이다.
모든 에 대하여 을 만족하는 양의 상수 와 가 존재하면, 이라고 정의한다. 은 모든 에 대해 의 값보다 크거나 같은 상한(Upper Bound) 역할을 한다
예: 은 도 되고, 도 되며, 도 됩니다. (더 큰 범위의 함수는 모두 상한이 될 수 있다)
예제1
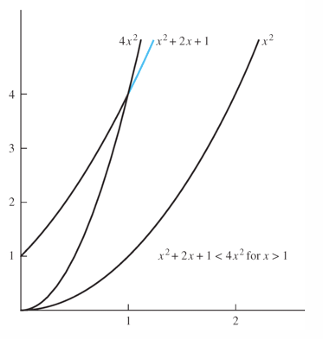
이 임을 증명한다. 증명을 위해서는 를 만족하는 상수 와 를 찾아야 한다.
- 가정: 이라고 가정해 본다. 그럼 다음이 성립한다
- 대입:
- 결론: 일 때 가 성립한다
- 따라서 일 때, 는 이다
예제2
이 임을 증명한다. 위와 동일한 논리로 더 큰 차수의 함수도 상한이 될 수 있음을 보여준다
- 가정: 이라고 가정해 본다. 그럼 다음이 성립한다
- 대입:
- 결론: 일 때 가 성립한다
- 따라서 일 때, 는 이다
표기법 (Omega Notation) - 하한선 Big-O가 “아무리 나빠도 이보다는 빠르다”는 상한선이라면, 는 **“아무리 빨라도 이보다는 느리다”**는 하한(Lower Bound)을 의미한다
오메가의 정의
모든 에 대하여 을 만족하는 양의 상수 와 가 존재하면 이다
알고리즘이 가장 최상의 시나리오에서도 최소한 만큼의 시간은 소요된다는 뜻이다
다항식의 경우: 이 차 다항식이고 최고차항 계수가 양수라면, 이 함수는 이 된다
표기법 (Theta Notation) - 딱 맞는 선 는 Big-O와 를 합친 개념으로, 알고리즘의 복잡도를 가장 정확하게 표현한다
세타의 정의
모든 에 대하여 을 만족하는 양의 상수 와 가 존재하면 이다
특징: 이 이면서 동시에 일 때 이라고 부른다. 상한과 하한이 같기 때문에 Big-O보다 훨씬 정밀한 지표이다
표기법 예시: 행렬 덧셈
void add(int a[][M_SIZE], ...) {
int i, j;
for(i = 0; i < rows; i++) //Theta(rows)
for(j = 0; j < cols; j++) //Theta(rows * cols)
c[i][j] = a[i][j] + b[i][j];//Theta(rows * cols)
} //총합:Theta(rows * cols)행렬 덧셈은 입력되는 행과 열의 크기에 정확히 비례하여 시간이 늘어 난다는 것을 의미한다
복잡도의 종류와 성장률
데이터 크기 이 커짐에 따라 각 함수가 출력하는 값의 차이가 얼마나 벌어지는지 표를 통해 알 수 있다
| 시간 복잡도 | 명칭 | n=1 | n=2 | n=4 | n=8 | 16 | 32 | 특징 |
|---|---|---|---|---|---|---|---|---|
| 1 | 상수 | 1 | 1 | 1 | 1 | 1 | 1 | 이상적 |
| 로그 | 0 | 1 | 2 | 3 | 4 | 5 | 효율적 | |
| 선형 | 1 | 2 | 4 | 8 | 16 | 32 | 준수함 | |
| 로그 선형 | 0 | 2 | 8 | 24 | 64 | 160 | 효율적인 정렬 알고리즘 수준 | |
| 2차 | 1 | 4 | 16 | 64 | 256 | 1024 | n이 커지면 부담됨 | |
| 3차 | 1 | 8 | 64 | 512 | 4096 | 32768 | 가급적 피해야 함 | |
| 지수 | 2 | 4 | 16 | 256 | 65536 | 4294967296 | 사용 불가 수준 | |
| 팩토리얼 | 1 | 2 | 24 | 40326 | 20922789888000 | 26313 x | 금지 |
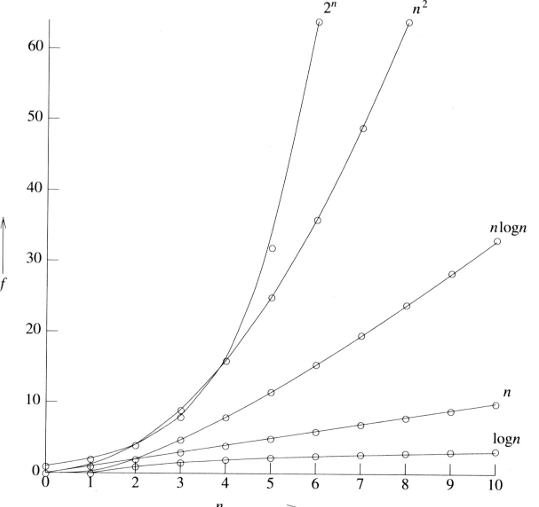
알고리즘 시간 복잡도의 성장 곡선 그래프는 n이 증가할 때 실행 시간이 얼마나 가파르게 상승하는지 보여준다
- 과 : 아주 작은 값에서도 수직에 가깝게 상승한다
- : 데이터가 많아져도 완만하게 상승하여 대용량 데이터 처리에 적합하다