자료구조란?
자료구조(Data Structure)
데이터 값의 모임, 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분하여 표현한 것이다
데이터 추상화(Data abstraction)
추상화를 이해하기 위해서는 먼저 데이터 타입이 무엇인지 알아야 한다
데이터 타입
데이터 타입(data type)
객체들의 집합과 그 객체들에 작용하는 연산의 집합을 의미한다
예시: int형
- 객체: 0, +1, -1, +2, -2,… , INT_MAX, INT_MIN}
- 연산: {+, -, *, /, %}
데이터 타입 종류
- 기본 타입: char, int, floot, double
- 복합 타입: 배열, 구조체
- 사용자 정의 타입: 프로그래머가 직접 정의하는 타입
추상 데이터 타입(ADT)
추상 데이터 타입(abstract data type, ADT)
데이터 객체와 그 연산의 명세가 실제 구현으로부터 분리된 데이터 타입이다
연산의 명세 포함 요소:
-
함수 이름
-
매개변수 타입
-
결과 값의 타입
-
함수가 하는 일에 대한 설명
ADT의 예시
추상화가 실제로 어떻게 적용되는지 자연수를 예로 들어보겠다
객체: 0에서 시작하여 시스템의 최대 정수까지의 순서화된 정수 부분 집합
주요 함수:
Zero(): 0을 반환함Add(x, y): 가 최대값을 넘지 않으면 합을 반환, 넘으면 최대값을 반환Subtract(x, y): 이면 0을 반환, 아니면 를 반환Equal(x, y): 와 가 같으면TRUE, 다르면FALSE반환Successor(x): 가 최대값이 아니면 을 반환
알고리즘
알고리즘
특정한 작업을 효율적으로 달성하기 위한 설계된 유한한 명령어들의 집합이다
알고리즘이 갖춰야 할 조건
- 입력 (Input): 외부에서 제공되는 데이터가 0개 이상 존재해야 함
- 출력 (Output): 적어도 1개 이상의 결과를 생성해야 함 (상태의 변화 포함)
- 명확성 (Definiteness): 각 단계는 모호하지 않고 명확해야 함
- 유한성 (Finiteness): 유한한 단계를 거친 후에는 반드시 종료되어야 함
- 유효성 (Effectiveness): 모든 명령어는 컴퓨터에서 실제로 실행 가능해야 함
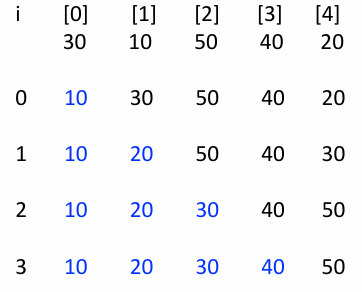
알고리즘: 선택 정렬(Selection Sort)
선택 정렬은 알고리즘의 기본 조건을 충족하면서, 데이터를 크기 순으로 나열하는 가장 직관적인 방법 중 하나이다
선택 정렬(Selection Sort)
정렬되지 않은 데이터중 가장 작은 값을 찾아, 정렬된 부분의 바로 다음 위치와 교체한다
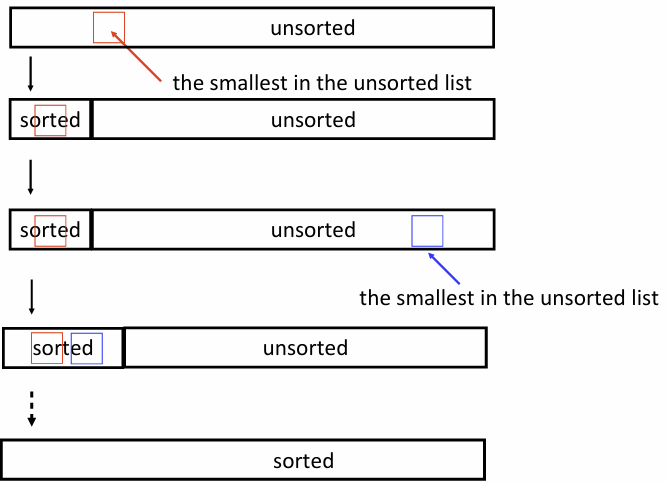
작동 원리
- 리스트를 정렬된 부분과 정렬되지 않는 부분으로 나눈다
- 정렬되지 않는 부분에서 최솟값을 찾는다
- 찾은 최솟값을 정렬되지 않은 부분의 첫 번째 원소와 자리를 바꾼다
- 이 과정을 정렬되지 않은 원소가 하나 남을 때까지 반복한다
의사코드
for (i = 0; i < n - 1; i++) { // 리스트의 원소 개수를 n이라고 할 때
// 1. list[i]부터 list[n-1]까지 검사하여 가장 작은 정수(즉, list[min])를 찾음
// 2. list[i]와 list[min]의 위치를 서로 교환(Interchange)함
}C언어 구현 코드
void sort(int list[], int n) {
int i, j, min, temp;
for (i = 0; i < n - 1; i++) {
min = i; // 현재 루프의 시작점을 일단 최솟값으로 가정
// 현재 위치(i) 이후의 원소들을 탐색하며 진짜 최솟값을 찾음
for (j = i + 1; j < n; j++) {
if (list[j] < list[min]) {
min = j; // 더 작은 값을 찾으면 min 인덱스 갱신
}
}
// SWAP: 찾은 최솟값(list[min])과 현재 위치(list[i])를 교환
// temp는 값을 잠시 보관하는 바구니 역할을 합니다.
temp = list[i];
list[i] = list[min];
list[min] = temp;
}
}실행 과정 테이블