파티셔닝(Partitioning): DB 스캔을 단 2회로 단축
Apriori 알고리즘의 고질적인 문제인 ‘반복적인 DB 스캔’을 해결하기 위한 접근 방식이다
기본 접근 방식*
- DB 분할: 전체 데이터베이스를 개의 조각(로컬 데이터베이스인 ‘파티션’ )으로 나눈다
- 각 파티션은 메인 메모리에 수용 가능한 크기여야 한다
- 1차 스캔 (Scan 1): 각 파티션에서 **로컬 빈번 패턴(Local frequent patterns)**을 찾는다
- 로컬 최소 지지도는 로 설정한다
- 특정 로컬 DB에서 지지도가 보다 큰 패턴들을 추출한다
- 2차 스캔 (Scan 2): 추출된 로컬 후보들을 모아 전체 DB에서 글로벌 빈번 패턴(Global frequent patterns)을 통합하여 확정한다
DHP 기법: 후보(Candidate)수의 획기적 감소
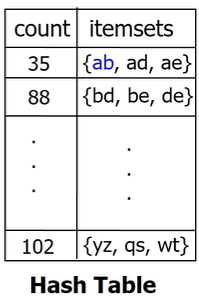
항목이 많아질수록 폭발적으로 증가하는 후보 항목집합의 수를 줄이기 위해 해시 테이블(Hash Table)을 활용한다
주요 원리:
- -항목집합을 결정하기 위한 DB 스캔 과정에서, 동시에 -항목집합을 위한 해시 테이블을 미리 구축한다
- 동기(Motivation): 항목이 10,000개라면 2-항목집합 후보는 무려 1억 개()에 달한다. 이를 효율적으로 필터링해야 한다
해시를 통한 가지치기(Pruning): 특정 해시 버킷의 카운트가 최소 지지도 미만이라면, 해당 버킷에 속한 어떤 항목집합도 빈번할 수 없다
- 예시: 항목집합가 같은 해시 버킷에 들어있을 때, 이 버킷의 전체 카운트 합이 최소 지지도 미만이라면, ab는 아예 2-항목집합 후보에서 제외된다. 특히 2-항목집합 후보의 수를 줄이는 데 매우 효과적이다
빈번 패턴 마이닝을 위한 샘플링
기본 접근 방식 전체 데이터베이스를 모두 뒤지는 대신 일부를 추출하여 효율성을 높이는 방식이다
- 방법: 원본 데이터베이스에서 샘플을 선택한 후, 해당 샘플 내에서 기존과 동일하게 Apriori 알고리즘 등을 사용하여 빈번 패턴()을 찾는다
- 지지도 설정: 샘플은 크기가 작으므로 원본보다 더 낮은 최소 지지도를 사용한다(예: 원래 최소 지지도의 수준)
- 목적: 계산 시간을 획기적으로 줄여 빠르게 대략적인 패턴을 파악하기 위함이다
단순 샘플링의 문제점* 샘플만 믿고 분석했을 때 두 가지 오류가 발생할 수 있다
- 가짜 빈번 패턴 (False Positives): 샘플에서는 빈번하게 나타났지만(), 실제 전체 데이터베이스에서는 빈번하지 않은 경우이다
- 누락된 빈번 패턴 (False Negatives): 실제로는 빈번한 패턴인데, 운 나쁘게 샘플에 포함되지 않아 발견되지 못하는 경우이다
해결책: 검증을 위한 추가 스캔
단순 샘플링의 오류를 해결하기 위해 전체 데이터베이스를 최대 두 번 더 스캔하여 정확도를 보장한다
추가 스캔 1: 전체 데이터베이스 1차 조사 샘플에서 찾은 패턴()과 부정 경계(Negative Borders, NB)를 검증한다
- 부정 경계(Negative Border, NB): 패턴 집합 에는 포함되지 않지만, 그 패턴의 모든 부분 집합(subset)은 에 포함되어 있는 항목집합을 말한다
- 예시: 만약 라면, 나 는 그 자체로 에 없지만 부분 집합()은 에 있으므로 부정 경계()가 된다
추가 스캔 2: 전체 데이터베이스 2차 조사
- 부정 경계() 중에서 실제 전체 데이터베이스에서 빈번한 것으로 판명된 패턴이 있다면, 이를 통해 누락될 뻔한 진짜 빈번 패턴들을 최종적으로 찾아낸다
DIC: 데이터베이스 스캔 횟수 줄이가
DIC 알고리즘은 전체 데이터베이스 스캔이 모두 끝나기만을 기다리지 않고, 스캔 도중에 가망 있는 후보들을 동적으로 추가하여 처리 효율을 극대화한다
핵싱 작동 원리 즉각적인 계산 시작: 특정 항목집합의 모든 부분 집합이 빈번하다고 판단되는 즉시, 전체 스캔이 끝나지 않았더라도 해당 항목집합의 빈도 계산을 시작한다
빈번 패턴 마이닝의 병목 현상
데이터의 크기가 커지고 패턴이 길어질수록 기존의 마이닝 방식은 심각한 성능 저하를 겪게 된다
주요 문제점
- 데이터베이스 스캔의 높은 비용: 데이터베이스를 여러 번 반복해서 읽는 과정(Multiple scans)은 시간과 자원 소모가 매우 크다
- 긴 패턴 마이닝의 어려움: 긴 패턴을 찾기 위해서는 그만큼 많은 횟수의 스캔이 필요하며, 이 과정에서 엄청난 수의 후보(Candidate) 항목집합이 생성된다
수치적 예시: 100개의 항목으로 구성된 패턴 길이가 100인 빈번 항목집합 을 찾는다고 가정할 때 발생하는 연산 부하이다
- 스캔 횟수: 총 100회의 데이터베이스 조회가 필요하다
- 생성되는 후보 수:
핵심 병목 및 새로운 방향
- 최종 병목(Bottleneck): “후보 생성 및 테스트(Candidate-generation-and-test)” 방식 자체가 마이닝의 속도를 늦추는 주범이다
- 핵심 과제: “후보 생성 자체를 아예 피할 수는 없을까?”라는 질문이 현대 데이터 마이닝 연구의 중요한 출발점이 된다
FP-Growth: 후보 생성 없는 빈번 패턴 마이닝
Apriori와 달리, FP-Growth는 후보를 일일이 만들고 테스트하지 않고 짧은 패턴에서 긴 패턴을 확장(Grow)하는 방식을 사용한다
핵심 원리: 로컬 빈번 항목을 사용하여 패턴을 키워나간다
작동 예시:
- “abc”가 빈번 패턴이라면, “abc”를 포함하는 모든 거래 데이터를 모은다 (이를 라고 표기함)
- 이 모아진 데이터() 안에서 “d”가 로컬하게 자주 나온다면(local frequent), “abcd” 역시 빈번 패턴이 된다
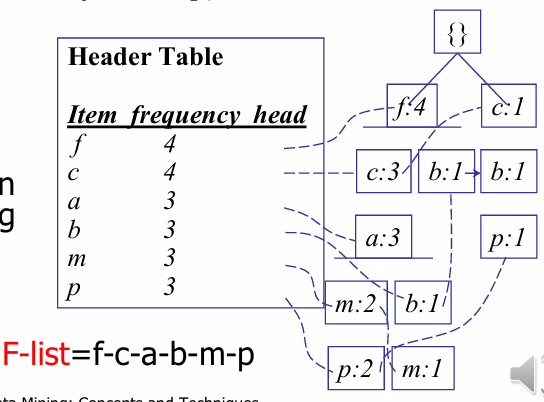
FP-tree 구축
데이터베이스를 효율적으로 압축하여 트리 형태로 만드는 과정이다
구축 단계
- .DB 1차 스캔: 빈번 1-항목집합(단일 항목 패턴)을 찾는다
- f-list 생성: 찾은 빈번 항목들을 빈도수가 높은 순서(내림차순)로 정렬한다
- DB 2차 스캔: 데이터를 다시 읽으며 FP-tree를 구축한다
- 각 거래 데이터에서 빈번하지 않은 항목은 버리고, f-list 순서에 맞춰 트리에 삽입한다
예시:

FP-tree 구조의 장점
FP-tree는 정보를 압축하면서도 마이닝에 필요한 모든 것을 담고 있는 매우 영리한 구조이다
완전성
- 빈번 패턴 마이닝을 위한 완전한 정보를 보존한다
- 거래 데이터의 긴 패턴을 절대 깨뜨리지 않고 그대로 담아낸다
압축성
- 불필요한 정보 제거: 빈번하지 않은 항목은 아예 트리에 넣지 않는다
- 공통 접두사 공유: 빈도가 높은 항목을 상단에 배치하여 여러 거래 데이터가 경로를 공유하게 만든다
- 효율성: 원본 데이터베이스보다 커지는 법이 없으며, 데이터에 따라 압축률이 100배 이상 되기도 한다
패턴과 데이터베이스의 분할
FP-Growth는 탐색 범위를 좁히기 위해 F-list(빈번 항목 리스트)를 기준으로 빈번 패턴들을 서로 겹치지 않는(disjoint) 부분 집합으로 분할한다
F-list 기반의 분할 예시 제시된 예시의 F-list 순서가 일 때, 마이닝 작업은 다음과 같이 나누어진다
- 를 포함하는 패턴: 전체 DB에서 가 포함된 부분만 집중적으로 탐색한다
- 은 포함하지만 는 없는 패턴: 를 제외한 나머지 데이터 중 이 포함된 부분을 탐색한다
- 는 포함하지만 과 는 없는 패턴: 이전 단계의 항목들을 제외하고 를 포함하는 패턴을 찾는다
- … (나머지 항목들도 동일한 방식으로 진행)
- 를 포함하지만 는 없는 패턴
- 단독 패턴
분할 전략의 두 가지 이점 이러한 체계적인 분할은 마이닝의 정확성과 효율성을 보장한다
- 완전성 (Completeness): 모든 가능한 빈번 패턴을 빠짐없이 찾아낼 수 있음을 보장한다
- 비중복성 (Non-redundancy): 각 부분 집합이 서로 겹치지 않게 설계되어 있어, 동일한 패턴을 여러 번 계산하는 낭비를 방지한다
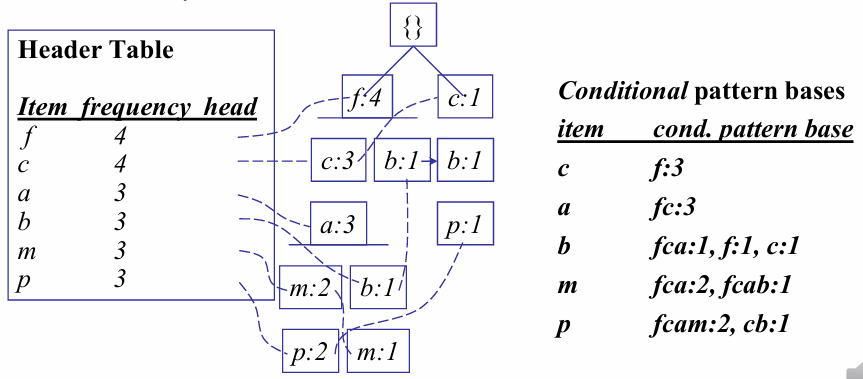
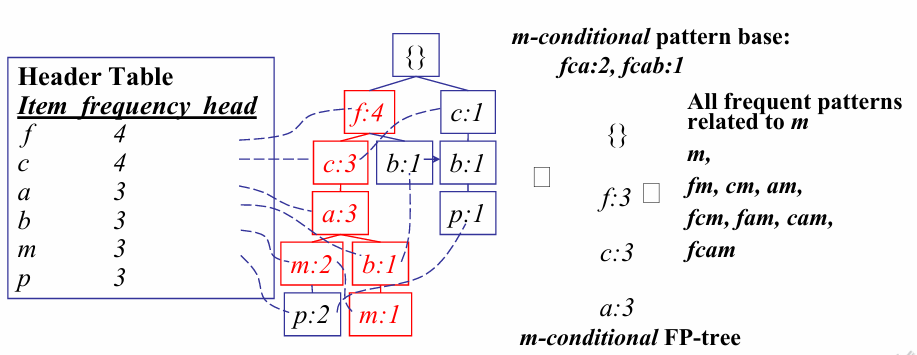
조건부 패턴 베이스 찾기(Conditional Pattern Base)
FP-tree를 구축한 후, 특정 항목()을 포함하는 패턴을 찾기 위해 조건부 패턴 베이스를 먼저 생성한다
수행 방법: FP-tree의 헤더 테이블(Header Table)에서 시작하여 특정 항목 의 링크를 따라 트리를 탐색한다
접두사 경로(Prefix Path): 항목 에 도달하기 전까지의 모든 경로(transformed prefix paths)를 모아 의 조건부 패턴 베이스를 형성한다
항목별 조건부 패턴 베이스 예시(F-list 역순):
조건부 FP-tree 생성(Conditional FP-trees)
각 조건부 패턴 베이스를 바탕으로 새로운 작은 트리를 만든다
수행 방법: 각 조건부 데이터베이스 내 항목들의 빈도수를 합산하고, 최소 지지도를 만족하는 항목들로만 다시 FP-tree를 구축한다
예시:
재귀적 마이닝(Recursive Mining)
조건부 FP-tree가 더 이상 쪼개지지 않을 때까지 이 과정을 재귀적으로 반복한다
- -조건부 FP-tree: “am”의 조건부 패턴 베이스는 이며, 이를 통해 형태의 트리를 얻는다
- -조건부 FP-tree: “cm”의 조건부 패턴 베이스는 이며, 단일 노드 트리가 된다
- -조건부 FP-tree: “cam”의 조건부 패턴 베이스는 이며, 이 또한 단일 노드 트리가 된다
특수한 경우: FP-tree 내의 단일 접두사 경로
FP-tree가 복잡하게 얽히지 않고, 하나의 공유된 단일 접두사 경로(Single prefix-path)를 가질 때 마이닝 효율을 더 높일 수 있다
- 상황 가정: (조건부) FP-tree 가 공통된 단일 접두사 경로 를 가지고 있을 때
- 분할 마이닝: 작업을 두 부분으로 나눈다
- 경로 축소: 단일 접두사 경로를 하나의 노드로 축소하여 재귀(recursion) 호출의 오버헤드를 줄인다
- 결과 결합: 축소된 부분과 나머지 부분의 마이닝 결과를 결합한다
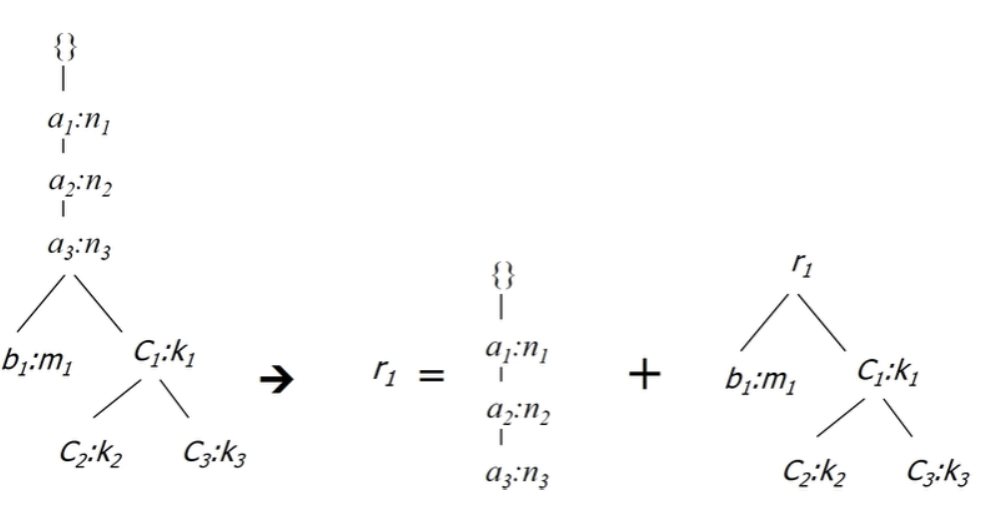
FP-Growth 알고리즘 핵심 요약
기본 아이디어: 빈번 항목을 재귀적으로 추가하면서 패턴을 확장(Grow)해 나가는 방식이다
주요 방법:
- 각 빈번 항목에 대해 조건부 패턴 베이스를 만든 후, 이를 바탕으로 조건부 FP-tree를 구축한다
- 새롭게 생성된 조건부 FP-tree 위에서 이 과정을 반복한다
종료 조건:
- 결과물인 FP-tree가 비어 있거나, 단일 경로(Single path)만 남았을 때 종료한다
- 단일 경로 규칙: 단일 경로는 해당 경로에 포함된 모든 부분 경로의 조합을 빈번 패턴으로 생성하며, 이 모든 조합은 빈번한 패턴이 된다