Frequent Pattern Analysis
빈번 패턴 분석(Frequent Pattern Analysis)
데이터 세트 내에서 빈번하게 발생하는 고유한 규칙성을 찾아내는 과정이다
Frequent 패턴 마이닝이 중요한 이유 단순한 통계를 넘어 데이터의 본질적인 특성을 드러내기 때문이다
- 데이터 세트의 핵심 속성을 보여준다
- 다양한 데이터 마이닝 작성의 기초를 형성한다
빈번 패턴과 연관 규칙(Frequent Patterns and Association Rules)
데이터 세트에서 항목 간의 상관관계를 분석하기 위한 기초 정의이다
트랜잭션(Transaction): 데이터베이스의 상태를 변화시키는 하나의 논리적 기능을 수행하기 위한 작업의 최소 단위이다
항목집합(Itemset): 와 같이 항목들의 모임을 의미한다
연관 규칙(Association Rules): 최소 지지도와 신뢰도를 만족하는 형태의 규칙을 찾는 것이 목적이다
- 지지도(Support,): 전체 트랜잭션 중 항목집합 와 를 모두 포함()할 확률이다
- 신뢰도 (Confidence, ): 항목집합 를 포함하는 트랜잭션이 도 포함할 조건부 확률이다
예시: (지지도): 50%, $conf_{min}(신뢰도): 50% 기준
: 연관 규칙:
- : 지지도 60%, 신뢰도 100%
- : 지지도 60%, 신뢰도 75%
폐쇄 패턴과 최대 패턴(Closed Patterns and Max-Patterns)
패턴이 길어질수록 부분 집합(Sub-patterns)의 수가 기하급수적으로 늘오나는 문제를 해결하기 위한 개념이다. 모든 하위 패턴을 일일이 찾는 대신, 정보를 대표할 수 있는 폐쇄 패턴과 최대 패턴만을 추출하여 효율을 높일 수 있다
폐쇄 패턴(Closed Patterns)
빈번하며, 자신과 동일한 지지도를 갖는 상위 패턴(Super-pattern)이 존재하지 않는 항목집합이다
특징: 비번 패턴 정보를 손실 없이 압축할 수 있다
최대 패턴(Max-Patterns
빈번하며, 자신을 포함하는 빈번한 상위 패턴이 존재하지 않는 항목집합이다
특징: 패턴의 수를 획기적으로 줄일 수 있다
연습 문제
조건: 데이터베이스 , 최소 지지도 () = 1
- 질문 1: 모든 빈번 패턴의 집합은?
- 답: (모든 조합의 수)
- 질문 2: 폐쇄 항목집합(Closed itemset)의 집합은?
- 답: (지지도 1), (지지도 2)
- 질문 3: 최대 패턴(Max-pattern)의 집합은?
- 답: (지지도 1)
빈번 패턴 마이닝을 위한 확장성 있는 방법(Scalable Methods for Mining Frequent Patterns)
빈번 패턴의 하향 폐쇄 성질 (The downward closure property of frequent patterns) 빈번 패턴 마이닝의 효율성을 획기적으로 높여주는 가장 중요한 이론적 배경이다
빈번 패턴의 하양 폐쇄 성질
빈번한 항목집합의 모든 부분 집합은 반드시 빈번해야 한다
- 예시: 만약 {맥주, 기저귀, 견과류}라는 항목집합이 빈번하다면, 그 부분 집합인 {맥주, 기저귀}도 반드시 빈번하다
- {맥주, 기저귀, 견과류}를 포함하는 모든 트랜잭션(거래 데이터)은 당연히 그 안에 {맥주, 기저귀}를 포함하고 있기 때문이다
확장성 있는 마이닝 방법: 세 가지 주요 접근 방식 이 분야에서 가장 널리 알려진 세 가지 알고리즘적 접근법이다
- Apriori:
- 하향 폐쇄 성질을 이용한 가장 기초적이고 고전적인 알고리즘
- FP-growth:
- 후보 생성 없이 ‘빈번 패턴 트리’를 구축하여 효율성을 극대화한 방식
- 수직 데이터 형식 접근법:
- Charm과 같이 데이터를 수직 구조로 변환하여 분석하는 방식
Apriori: 후보 생성 및 테스트 접근법
Apriori 알고리즘은 “가지치기(Pruning)” 원리를 통해 탐색 범위를 줄이는 것이 핵심이다
가지치기 원리: 만약 어떤 항목집합이 빈번하지 않다면, 그 항목집합을 포함하는 상위 집합 또한 빈번할 수 없으므로 생성하거나 테스트 하지 않는다
작동 방법:
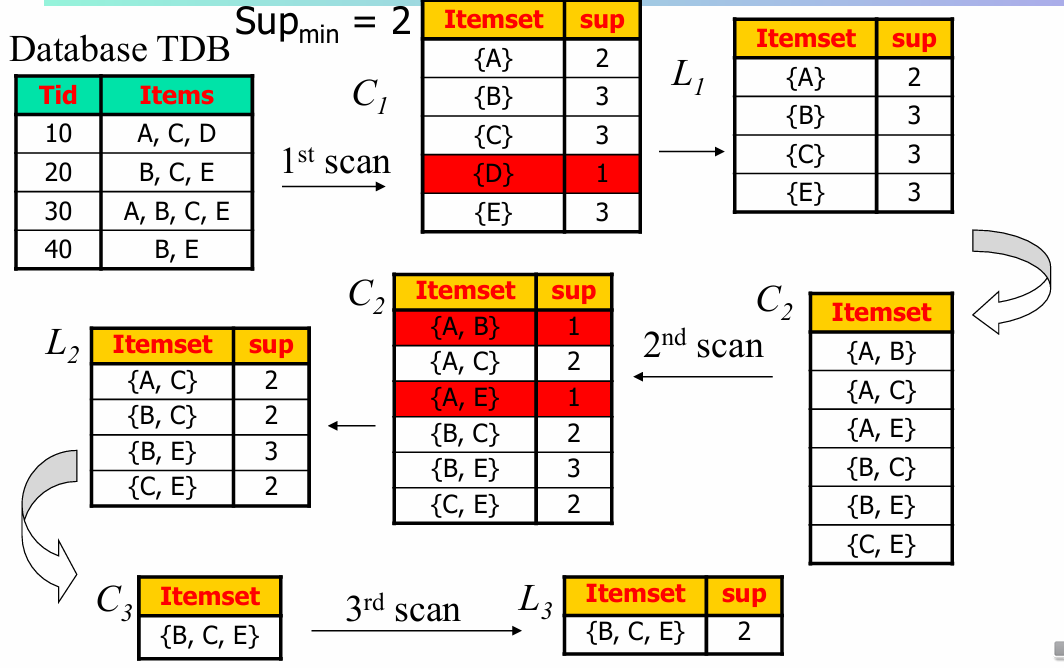
- DB를 한 번 스캔하여 빈번한 1-항목집합()을 구한다
- 빈번한 -항목집합()으로부터 길이가 인 후보 항목집합()을 생성한다
- 후보 집합들을 DB와 대조하여 테스트한다
- 더 이상 빈번 항목집합이나 후보 집합을 생성할 수 없을 때 종료한다
예시:
Pseudo-code:
C_k: 크기가 k인 후보(Candidate) 항목집합
L_k: 크기가 k인 빈번(Frequent) 항목집합
L_1 = {빈번한 단일 항목들}; // DB를 1차 스캔하여 지지도를 만족하는 항목 추출
for (k = 1; L_k != Ø; k++) do begin
// 1. 후보 생성: 빈번 항목집합 L_k를 결합하여 한 단계 큰 후보군 생성
C_{k+1} = candidates generated from L_k;
// 2. 지지도 계산: 데이터베이스의 각 트랜잭션(t)을 확인
for each transaction t in database do begin
// 트랜잭션 t에 포함된 후보들의 카운트 증가
increment the count of all candidates in C_{k+1} that are contained in t;
end
// 3. 필터링: 최소 지지도를 만족하는 후보들만 빈번 항목집합으로 확정
L_{k+1} = candidates in C_{k+1} with min_support;
end
return ∪_k L_k; // 찾은 모든 빈번 항목집합의 합집합을 반환후보 생성의 상세 과정 후보군을 만들 때는 다음의 두 단계를 거친다
- 1단계: 자기 결합(Self-joining) : 빈번 항목집합끼리 결합하여 더 긴 후보를 만든다
- 예시: 와 를 결합하여 생성
- 2단계: 가지치기(Pruning): 생성된 후보의 모든 부분 집합이 빈번한지 확인한다. 하나라도 빈번하지 않다면 그 후보는 제거한다
- 예시: 의 부분 집합인 가 빈번 항목집합()에 없다면 는 후보에서 제거한다
빈번 패턴 마이닝의 과제와 개선 방향
Apriori 알고리즘은 구현이 쉽지만 대규모 데이터에서는 다음과 같은 한계가 있다
-
주요 한계(Challenges):
- 트랜잭션 데이터베이스를 여러 번 반복해서 스캔해야 함
- 생성되는 후보 항목집합의 수가 너무 많음
- 후보들의 지지도를 일일이 세는 작업이 매우 무겁고 지루함
-
개선 아이디어:
- DB 스캔 횟수 줄이기
- 후보 항목집합의 수 축소하기
- 후보의 지지도 계산 과정을 더 쉽게 만들기